 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRSCA: Real-time Segmentation-based Context-Aware Scene Text Detection
Paper and Code
May 26, 2021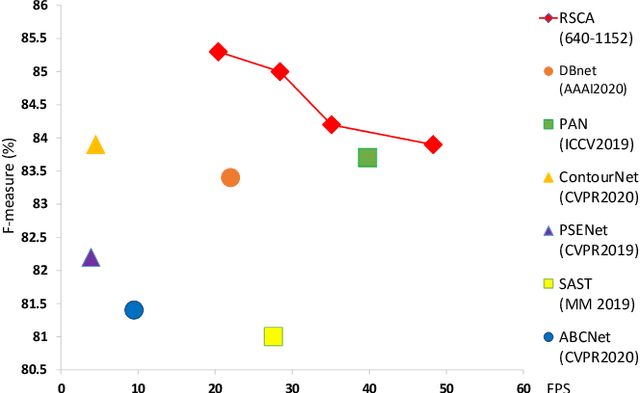
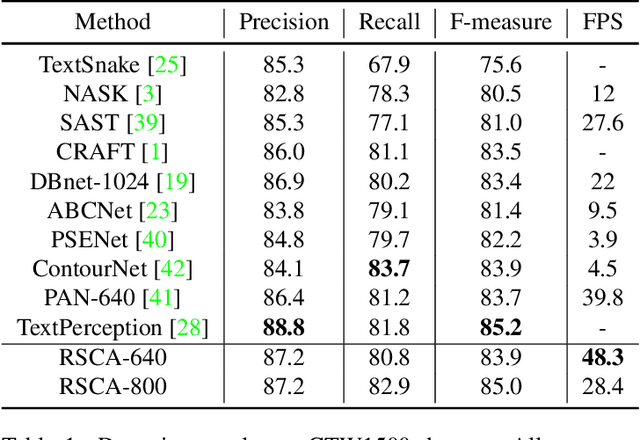
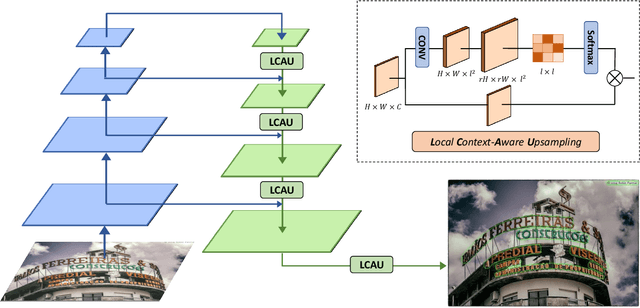
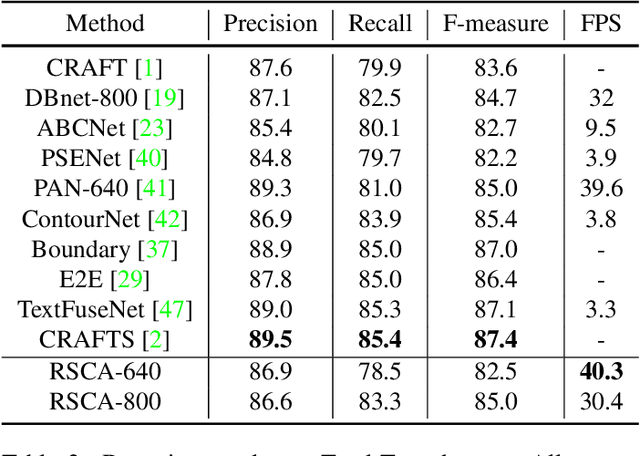
Segmentation-based scene text detection methods have been widely adopted for arbitrary-shaped text detection recently, since they make accurate pixel-level predictions on curved text instances and can facilitate real-time inference without time-consuming processing on anchors. However, current segmentation-based models are unable to learn the shapes of curved texts and often require complex label assignments or repeated feature aggregations for more accurate detection. In this paper, we propose RSCA: a Real-time Segmentation-based Context-Aware model for arbitrary-shaped scene text detection, which sets a strong baseline for scene text detection with two simple yet effective strategies: Local Context-Aware Upsampling and Dynamic Text-Spine Labeling, which model local spatial transformation and simplify label assignments separately. Based on these strategies, RSCA achieves state-of-the-art performance in both speed and accuracy, without complex label assignments or repeated feature aggregations. We conduct extensive experiments on multiple benchmarks to validate the effectiveness of our method. RSCA-640 reaches 83.9% F-measure at 48.3 FPS on CTW1500 dataset.