 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRREx-BoT: Remote Referring Expressions with a Bag of Tricks
Paper and Code
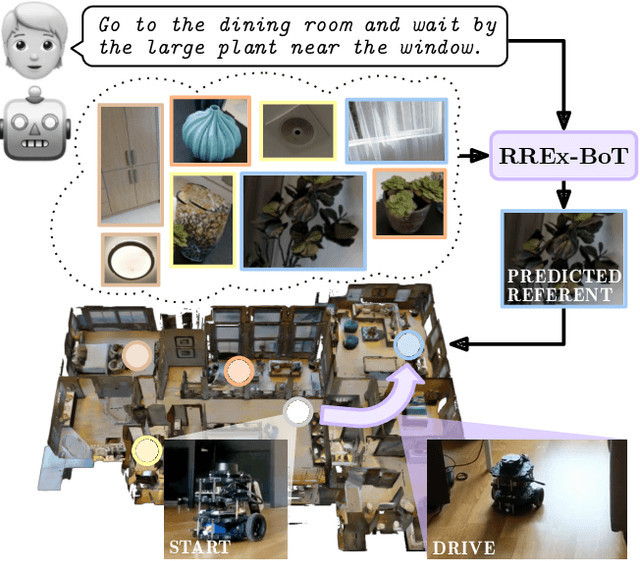
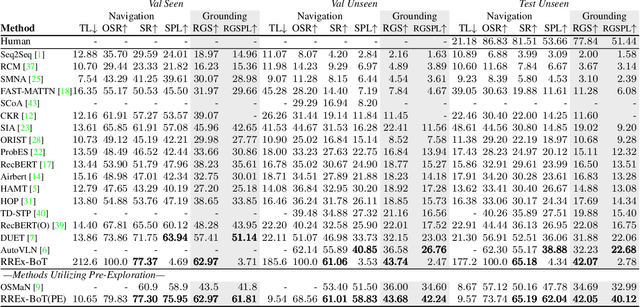
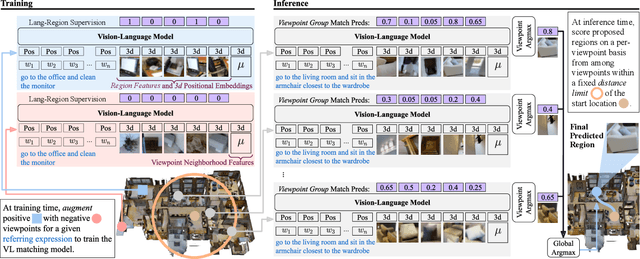
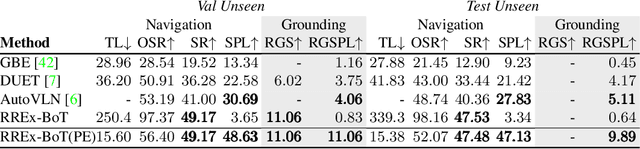
Household robots operate in the same space for years. Such robots incrementally build dynamic maps that can be used for tasks requiring remote object localization. However, benchmarks in robot learning often test generalization through inference on tasks in unobserved environments. In an observed environment, locating an object is reduced to choosing from among all object proposals in the environment, which may number in the 100,000s. Armed with this intuition, using only a generic vision-language scoring model with minor modifications for 3d encoding and operating in an embodied environment, we demonstrate an absolute performance gain of 9.84% on remote object grounding above state of the art models for REVERIE and of 5.04% on FAO. When allowed to pre-explore an environment, we also exceed the previous state of the art pre-exploration method on REVERIE. Additionally, we demonstrate our model on a real-world TurtleBot platform, highlighting the simplicity and usefulness of the approach. Our analysis outlines a "bag of tricks" essential for accomplishing this task, from utilizing 3d coordinates and context, to generalizing vision-language models to large 3d search spaces.