 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRotation Invariant Transformer for Recognizing Object in UAVs
Paper and Code

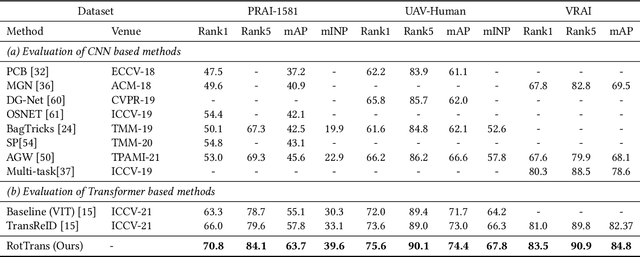
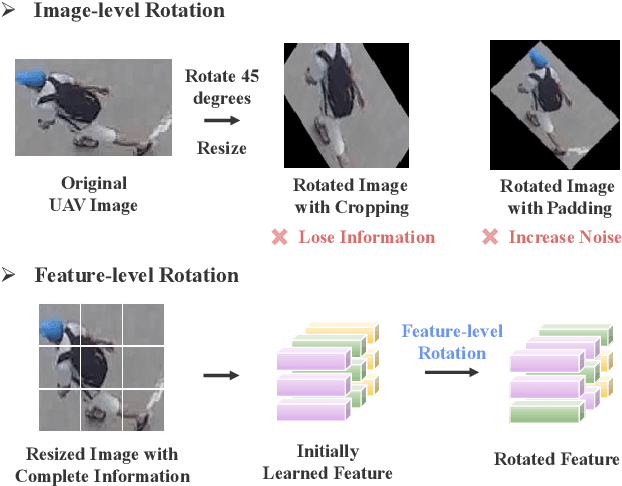
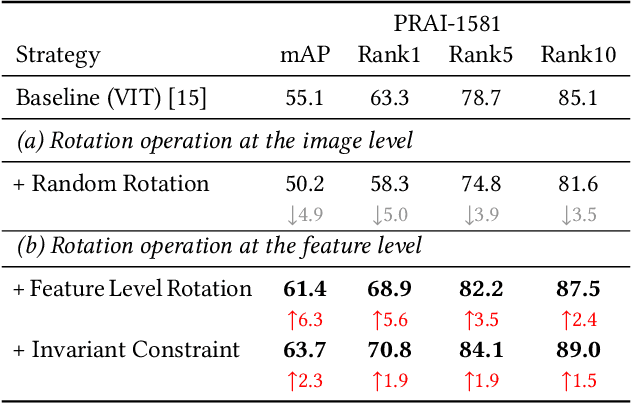
Recognizing a target of interest from the UAVs is much more challenging than the existing object re-identification tasks across multiple city cameras. The images taken by the UAVs usually suffer from significant size difference when generating the object bounding boxes and uncertain rotation variations. Existing methods are usually designed for city cameras, incapable of handing the rotation issue in UAV scenarios. A straightforward solution is to perform the image-level rotation augmentation, but it would cause loss of useful information when inputting the powerful vision transformer as patches. This motivates us to simulate the rotation operation at the patch feature level, proposing a novel rotation invariant vision transformer (RotTrans). This strategy builds on high-level features with the help of the specificity of the vision transformer structure, which enhances the robustness against large rotation differences. In addition, we design invariance constraint to establish the relationship between the original feature and the rotated features, achieving stronger rotation invariance. Our proposed transformer tested on the latest UAV datasets greatly outperforms the current state-of-the-arts, which is 5.9\% and 4.8\% higher than the highest mAP and Rank1. Notably, our model also performs competitively for the person re-identification task on traditional city cameras. In particular, our solution wins the first place in the UAV-based person re-recognition track in the Multi-Modal Video Reasoning and Analyzing Competition held in ICCV 2021. Code is available at https://github.com/whucsy/RotTrans.