 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Explainability: A Tutorial on Gradient-Based Attribution Methods for Deep Neural Networks
Paper and Code
Jul 28, 2021

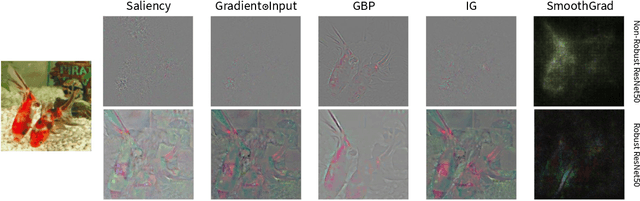
With the rise of deep neural networks, the challenge of explaining the predictions of these networks has become increasingly recognized. While many methods for explaining the decisions of deep neural networks exist, there is currently no consensus on how to evaluate them. On the other hand, robustness is a popular topic for deep learning research; however, it is hardly talked about in explainability until very recently. In this tutorial paper, we start by presenting gradient-based interpretability methods. These techniques use gradient signals to assign the burden of the decision on the input features. Later, we discuss how gradient-based methods can be evaluated for their robustness and the role that adversarial robustness plays in having meaningful explanations. We also discuss the limitations of gradient-based methods. Finally, we present the best practices and attributes that should be examined before choosing an explainability method. We conclude with the future directions for research in the area at the convergence of robustness and explainability.