 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Provably Monotonic Networks
Paper and Code
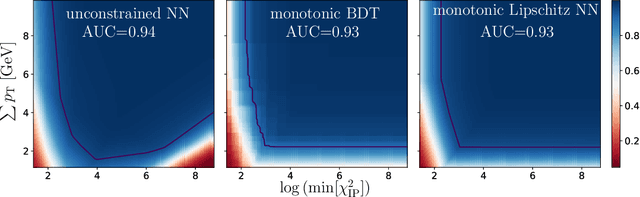
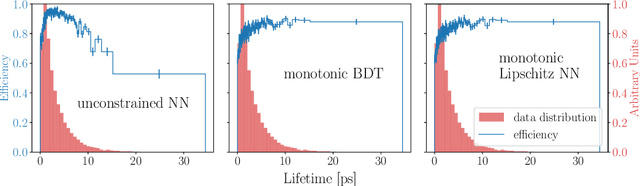

The Lipschitz constant of the map between the input and output space represented by a neural network is a natural metric for assessing the robustness of the model. We present a new method to constrain the Lipschitz constant of dense deep learning models that can also be generalized to other architectures. The method relies on a simple weight normalization scheme during training that ensures the Lipschitz constant of every layer is below an upper limit specified by the analyst. A simple residual connection can then be used to make the model monotonic in any subset of its inputs, which is useful in scenarios where domain knowledge dictates such dependence. Examples can be found in algorithmic fairness requirements or, as presented here, in the classification of the decays of subatomic particles produced at the CERN Large Hadron Collider. Our normalization is minimally constraining and allows the underlying architecture to maintain higher expressiveness compared to other techniques which aim to either control the Lipschitz constant of the model or ensure its monotonicity. We show how the algorithm was used to train a powerful, robust, and interpretable discriminator for heavy-flavor decays in the LHCb realtime data-processing system.