 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust 3D-aware Object Classification via Discriminative Render-and-Compare
Paper and Code
May 24, 2023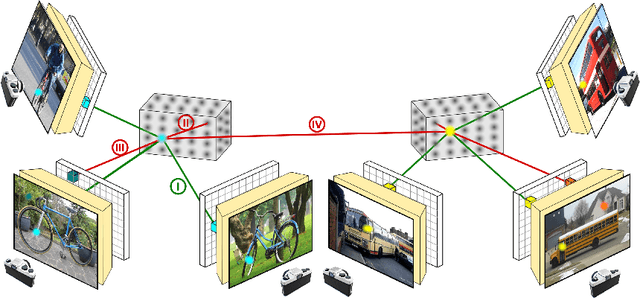
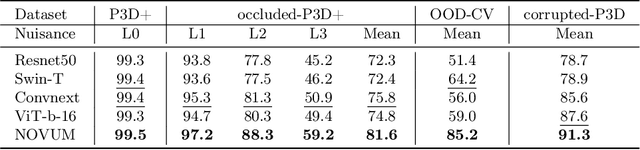
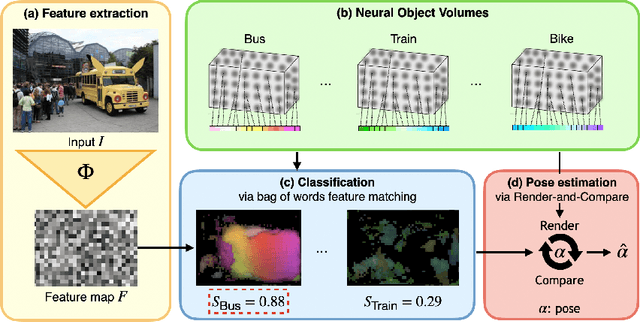
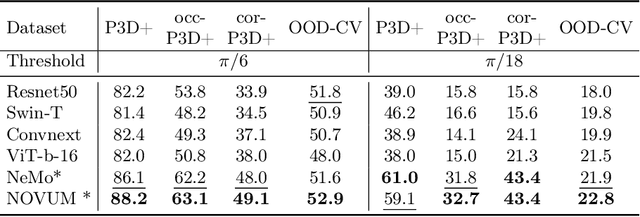
In real-world applications, it is essential to jointly estimate the 3D object pose and class label of objects, i.e., to perform 3D-aware classification.While current approaches for either image classification or pose estimation can be extended to 3D-aware classification, we observe that they are inherently limited: 1) Their performance is much lower compared to the respective single-task models, and 2) they are not robust in out-of-distribution (OOD) scenarios. Our main contribution is a novel architecture for 3D-aware classification, which builds upon a recent work and performs comparably to single-task models while being highly robust. In our method, an object category is represented as a 3D cuboid mesh composed of feature vectors at each mesh vertex. Using differentiable rendering, we estimate the 3D object pose by minimizing the reconstruction error between the mesh and the feature representation of the target image. Object classification is then performed by comparing the reconstruction losses across object categories. Notably, the neural texture of the mesh is trained in a discriminative manner to enhance the classification performance while also avoiding local optima in the reconstruction loss. Furthermore, we show how our method and feed-forward neural networks can be combined to scale the render-and-compare approach to larger numbers of categories. Our experiments on PASCAL3D+, occluded-PASCAL3D+, and OOD-CV show that our method outperforms all baselines at 3D-aware classification by a wide margin in terms of performance and robustness.