 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRisk-Aware Linear Bandits: Theory and Applications in Smart Order Routing
Paper and Code
Aug 04, 2022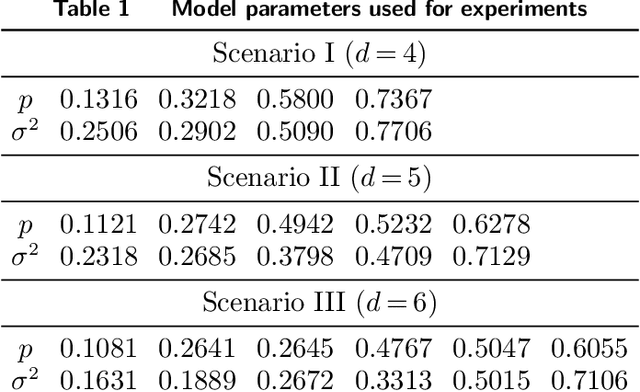
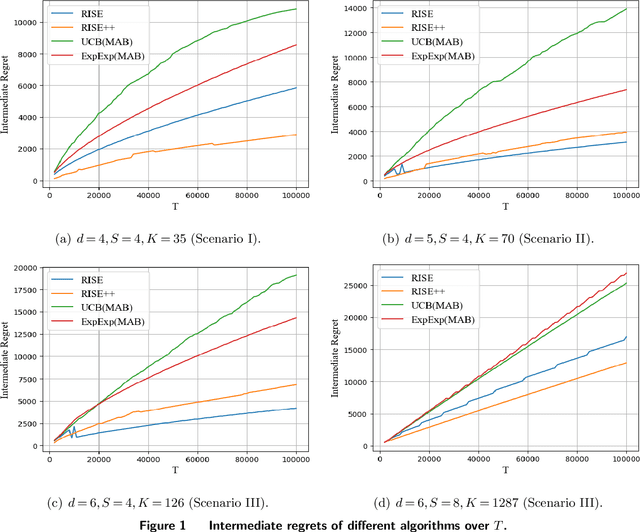
Motivated by practical considerations in machine learning for financial decision-making, such as risk-aversion and large action space, we initiate the study of risk-aware linear bandits. Specifically, we consider regret minimization under the mean-variance measure when facing a set of actions whose rewards can be expressed as linear functions of (initially) unknown parameters. Driven by the variance-minimizing G-optimal design, we propose the Risk-Aware Explore-then-Commit (RISE) algorithm and the Risk-Aware Successive Elimination (RISE++) algorithm. Then, we rigorously analyze their regret upper bounds to show that, by leveraging the linear structure, the algorithms can dramatically reduce the regret when compared to existing methods. Finally, we demonstrate the performance of the algorithms by conducting extensive numerical experiments in a synthetic smart order routing setup. Our results show that both RISE and RISE++ can outperform the competing methods, especially in complex decision-making scenarios.