 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRIIT: Rethinking the Importance of Implementation Tricks in Multi-Agent Reinforcement Learning
Paper and Code
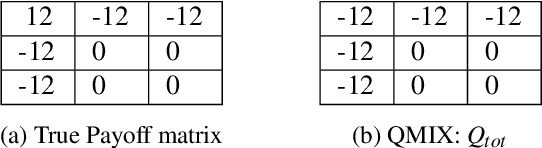


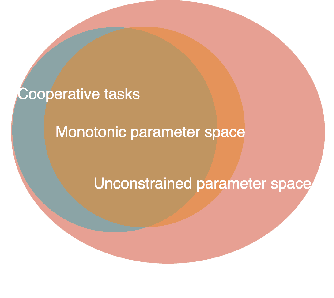
In recent years, Multi-Agent Deep Reinforcement Learning (MADRL) has been successfully applied to various complex scenarios such as computer games and robot swarms. We investigate the impact of "implementation tricks" of state-of-the-art (SOTA) QMIX-based algorithms. Firstly, we find that such tricks, described as auxiliary details to the core algorithm, seemingly of secondary importance, have a major impact. Our finding demonstrates that, after minimal tuning, QMIX attains extraordinarily high win rates and achieves SOTA in the StarCraft Multi-Agent Challenge (SMAC). Furthermore, we find QMIX's monotonicity condition helps improve sample efficiency in some cooperative tasks, and we propose a new policy-based algorithm, called: RIIT, to prove the importance of the monotonicity condition. RIIT also achieves SOTA in policy-based algorithms. At last, we propose a hypothesis to explain the monotonicity condition. We open-sourced the code at \url{https://github.com/hijkzzz/pymarl2}.