 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting the Characteristics of Stochastic Gradient Noise and Dynamics
Paper and Code

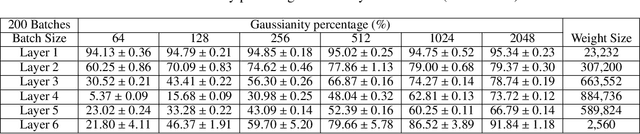


In this paper, we characterize the noise of stochastic gradients and analyze the noise-induced dynamics during training deep neural networks by gradient-based optimizers. Specifically, we firstly show that the stochastic gradient noise possesses finite variance, and therefore the classical Central Limit Theorem (CLT) applies; this indicates that the gradient noise is asymptotically Gaussian. Such an asymptotic result validates the wide-accepted assumption of Gaussian noise. We clarify that the recently observed phenomenon of heavy tails within gradient noise may not be intrinsic properties, but the consequence of insufficient mini-batch size; the gradient noise, which is a sum of limited i.i.d. random variables, has not reached the asymptotic regime of CLT, thus deviates from Gaussian. We quantitatively measure the goodness of Gaussian approximation of the noise, which supports our conclusion. Secondly, we analyze the noise-induced dynamics of stochastic gradient descent using the Langevin equation, granting for momentum hyperparameter in the optimizer with a physical interpretation. We then proceed to demonstrate the existence of the steady-state distribution of stochastic gradient descent and approximate the distribution at a small learning rate.