 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReverse Training to Nurse the Reversal Curse
Paper and Code
Mar 20, 2024


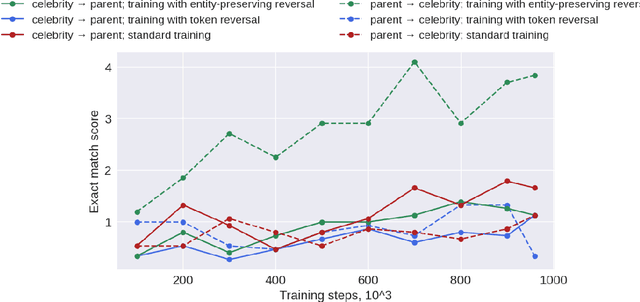
Large language models (LLMs) have a surprising failure: when trained on "A has a feature B", they do not generalize to "B is a feature of A", which is termed the Reversal Curse. Even when training with trillions of tokens this issue still appears due to Zipf's law - hence even if we train on the entire internet. This work proposes an alternative training scheme, called reverse training, whereby all words are used twice, doubling the amount of available tokens. The LLM is trained in both forward and reverse directions by reversing the training strings while preserving (i.e., not reversing) chosen substrings, such as entities. We show that data-matched reverse-trained models provide superior performance to standard models on standard tasks, and compute-matched reverse-trained models provide far superior performance on reversal tasks, helping resolve the reversal curse issue.