 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Re-Sampling in Imbalanced Semi-Supervised Learning
Paper and Code
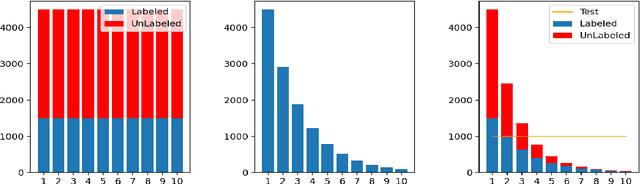
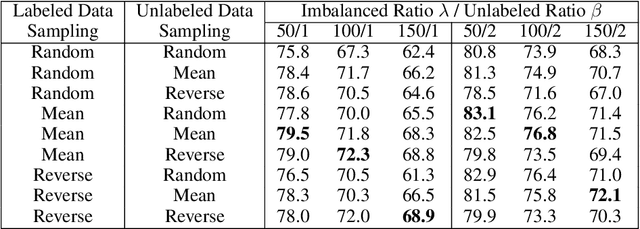
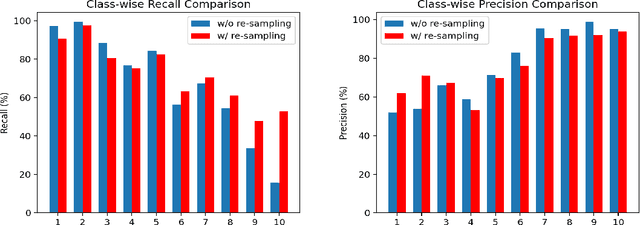
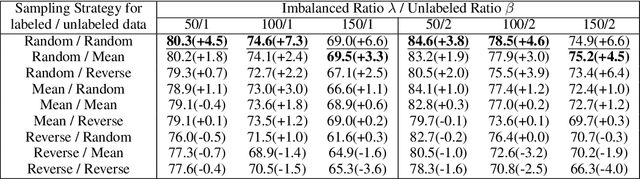
Semi-Supervised Learning (SSL) has shown its strong ability in utilizing unlabeled data when labeled data is scarce. However, most SSL algorithms work under the assumption that the class distributions are balanced in both training and test sets. In this work, we consider the problem of SSL on class-imbalanced data, which better reflects real-world situations but has only received limited attention so far. In particular, we decouple the training of the representation and the classifier, and systematically investigate the effects of different data re-sampling techniques when training the whole network including a classifier as well as fine-tuning the feature extractor only. We find that data re-sampling is of critical importance to learn a good classifier as it increases the accuracy of the pseudo-labels, in particular for the minority classes in the unlabeled data. Interestingly, we find that accurate pseudo-labels do not help when training the feature extractor, rather contrariwise, data re-sampling harms the training of the feature extractor. This finding is against the general intuition that wrong pseudo-labels always harm the model performance in SSL. Based on these findings, we suggest to re-think the current paradigm of having a single data re-sampling strategy and develop a simple yet highly effective Bi-Sampling (BiS) strategy for SSL on class-imbalanced data. BiS implements two different re-sampling strategies for training the feature extractor and the classifier and integrates this decoupled training into an end-to-end framework... Code will be released at https://github.com/TACJu/Bi-Sampling.