 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Information Loss in Medical Image Segmentation with Various-sized Targets
Paper and Code
Mar 28, 2024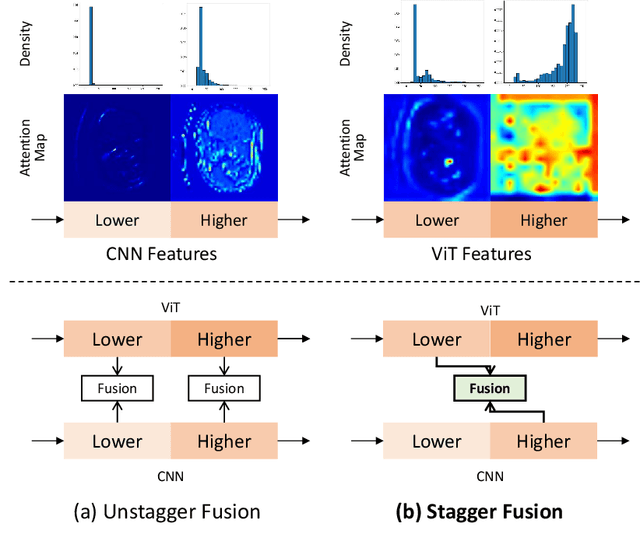



Medical image segmentation presents the challenge of segmenting various-size targets, demanding the model to effectively capture both local and global information. Despite recent efforts using CNNs and ViTs to predict annotations of different scales, these approaches often struggle to effectively balance the detection of targets across varying sizes. Simply utilizing local information from CNNs and global relationships from ViTs without considering potential significant divergence in latent feature distributions may result in substantial information loss. To address this issue, in this paper, we will introduce a novel Stagger Network (SNet) and argues that a well-designed fusion structure can mitigate the divergence in latent feature distributions between CNNs and ViTs, thereby reducing information loss. Specifically, to emphasize both global dependencies and local focus, we design a Parallel Module to bridge the semantic gap. Meanwhile, we propose the Stagger Module, trying to fuse the selected features that are more semantically similar. An Information Recovery Module is further adopted to recover complementary information back to the network. As a key contribution, we theoretically analyze that the proposed parallel and stagger strategies would lead to less information loss, thus certifying the SNet's rationale. Experimental results clearly proved that the proposed SNet excels comparisons with recent SOTAs in segmenting on the Synapse dataset where targets are in various sizes. Besides, it also demonstrates superiority on the ACDC and the MoNuSeg datasets where targets are with more consistent dimensions.