 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Experience Replay: a Bag of Tricks for Continual Learning
Paper and Code
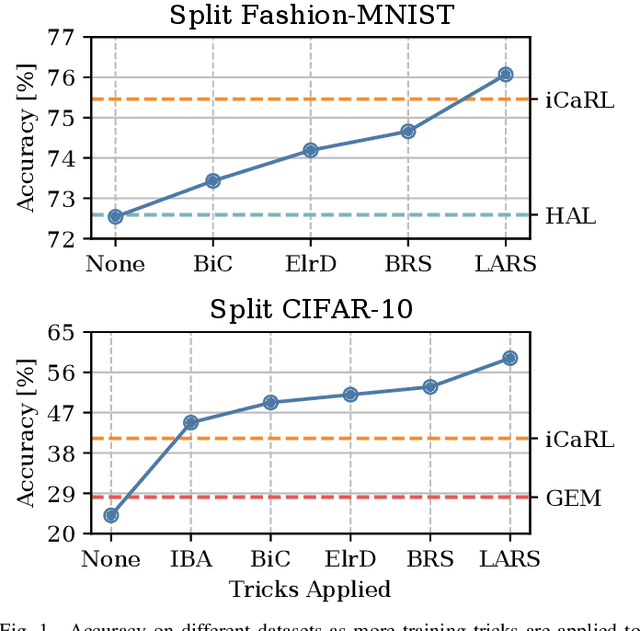
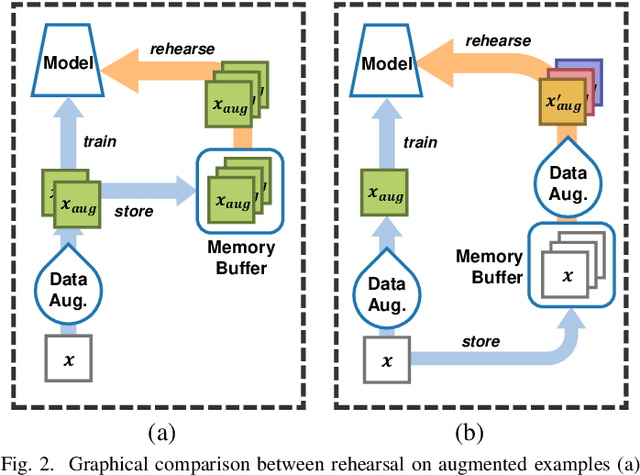

In Continual Learning, a Neural Network is trained on a stream of data whose distribution shifts over time. Under these assumptions, it is especially challenging to improve on classes appearing later in the stream while remaining accurate on previous ones. This is due to the infamous problem of catastrophic forgetting, which causes a quick performance degradation when the classifier focuses on learning new categories. Recent literature proposed various approaches to tackle this issue, often resorting to very sophisticated techniques. In this work, we show that naive rehearsal can be patched to achieve similar performance. We point out some shortcomings that restrain Experience Replay (ER) and propose five tricks to mitigate them. Experiments show that ER, thus enhanced, displays an accuracy gain of 51.2 and 26.9 percentage points on the CIFAR-10 and CIFAR-100 datasets respectively (memory buffer size 1000). As a result, it surpasses current state-of-the-art rehearsal-based methods.