 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Collaborative Metric Learning: Toward an Efficient Alternative without Negative Sampling
Paper and Code

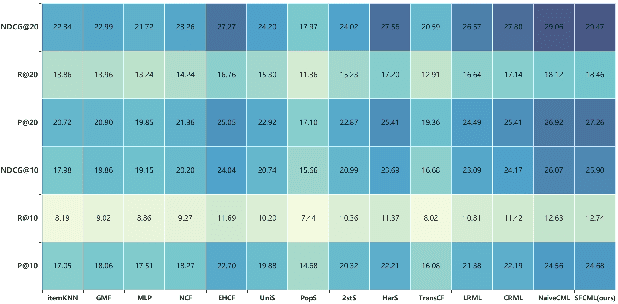

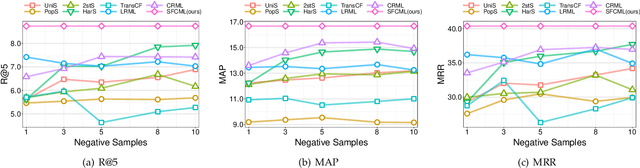
The recently proposed Collaborative Metric Learning (CML) paradigm has aroused wide interest in the area of recommendation systems (RS) owing to its simplicity and effectiveness. Typically, the existing literature of CML depends largely on the \textit{negative sampling} strategy to alleviate the time-consuming burden of pairwise computation. However, in this work, by taking a theoretical analysis, we find that negative sampling would lead to a biased estimation of the generalization error. Specifically, we show that the sampling-based CML would introduce a bias term in the generalization bound, which is quantified by the per-user \textit{Total Variance} (TV) between the distribution induced by negative sampling and the ground truth distribution. This suggests that optimizing the sampling-based CML loss function does not ensure a small generalization error even with sufficiently large training data. Moreover, we show that the bias term will vanish without the negative sampling strategy. Motivated by this, we propose an efficient alternative without negative sampling for CML named \textit{Sampling-Free Collaborative Metric Learning} (SFCML), to get rid of the sampling bias in a practical sense. Finally, comprehensive experiments over seven benchmark datasets speak to the superiority of the proposed algorithm.