 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResource-Efficient Invariant Networks: Exponential Gains by Unrolled Optimization
Paper and Code
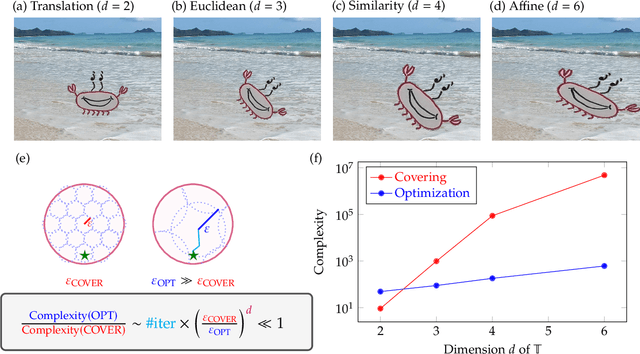
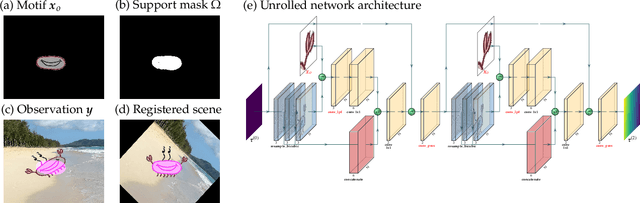
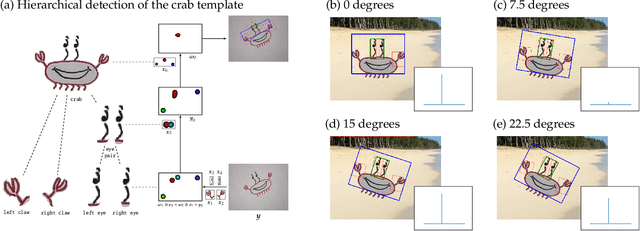
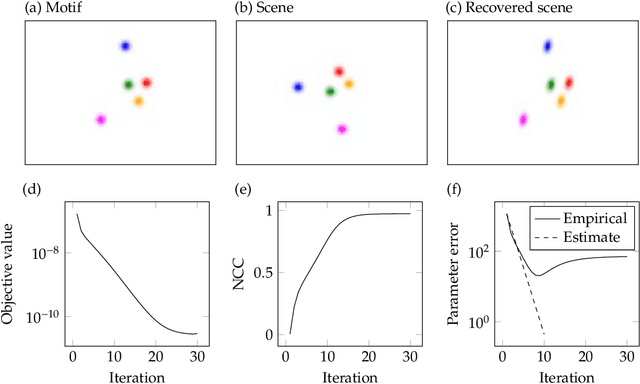
Achieving invariance to nuisance transformations is a fundamental challenge in the construction of robust and reliable vision systems. Existing approaches to invariance scale exponentially with the dimension of the family of transformations, making them unable to cope with natural variabilities in visual data such as changes in pose and perspective. We identify a common limitation of these approaches--they rely on sampling to traverse the high-dimensional space of transformations--and propose a new computational primitive for building invariant networks based instead on optimization, which in many scenarios provides a provably more efficient method for high-dimensional exploration than sampling. We provide empirical and theoretical corroboration of the efficiency gains and soundness of our proposed method, and demonstrate its utility in constructing an efficient invariant network for a simple hierarchical object detection task when combined with unrolled optimization. Code for our networks and experiments is available at https://github.com/sdbuch/refine.