 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResisting Adversarial Attacks by $k$-Winners-Take-All
Paper and Code



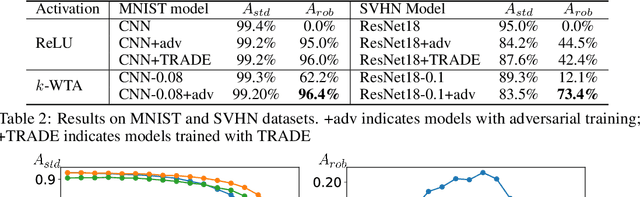
We propose a simple change to the current neural network structure for defending against gradient-based adversarial attacks. Instead of using popular activation functions (such as ReLU), we advocate the use of $k$-Winners-Take-All ($k$-WTA) activation, a $C^0$ discontinuous function that purposely invalidates the neural network model's gradient at densely distributed input data points. Our proposal is theoretically rationalized. We show why the discontinuities in $k$-WTA networks can largely prevent gradient-based search of adversarial examples and why they at the same time remain innocuous to the network training. This understanding is also empirically backed. Even without notoriously expensive adversarial training, the robustness performance of our networks is comparable to conventional ReLU networks optimized by adversarial training. Furthermore, after also optimized through adversarial training, our networks outperform the state-of-the-art methods under white-box attacks on various datasets that we experimented with.