 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeResidual Adapters for Few-Shot Text-to-Speech Speaker Adaptation
Paper and Code
Oct 28, 2022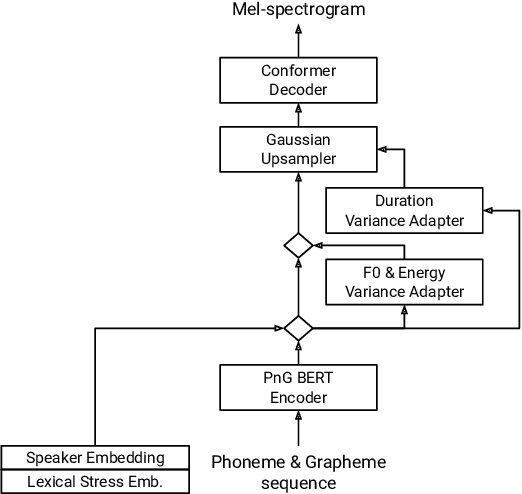



Adapting a neural text-to-speech (TTS) model to a target speaker typically involves fine-tuning most if not all of the parameters of a pretrained multi-speaker backbone model. However, serving hundreds of fine-tuned neural TTS models is expensive as each of them requires significant footprint and separate computational resources (e.g., accelerators, memory). To scale speaker adapted neural TTS voices to hundreds of speakers while preserving the naturalness and speaker similarity, this paper proposes a parameter-efficient few-shot speaker adaptation, where the backbone model is augmented with trainable lightweight modules called residual adapters. This architecture allows the backbone model to be shared across different target speakers. Experimental results show that the proposed approach can achieve competitive naturalness and speaker similarity compared to the full fine-tuning approaches, while requiring only $\sim$0.1% of the backbone model parameters for each speaker.