 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRényi Divergence Deep Mutual Learning
Paper and Code
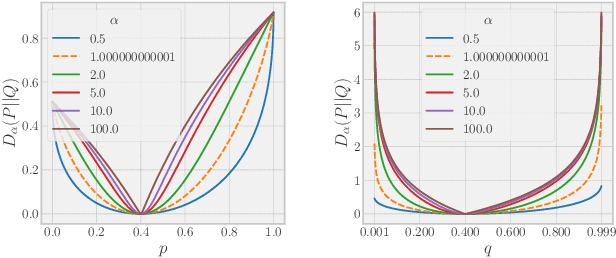


This paper revisits an incredibly simple yet exceedingly effective computing paradigm, Deep Mutual Learning (DML). We observe that the effectiveness correlates highly to its excellent generalization quality. In the paper, we interpret the performance improvement with DML from a novel perspective that it is roughly an approximate Bayesian posterior sampling procedure. This also establishes the foundation for applying the R\'{e}nyi divergence to improve the original DML, as it brings in the variance control of the prior (in the context of DML). Therefore, we propose R\'{e}nyi Divergence Deep Mutual Learning (RDML). Our empirical results represent the advantage of the marriage of DML and the R\'{e}nyi divergence. The flexible control imposed by the R\'{e}nyi divergence is able to further improve DML to learn better generalized models.