 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative stability toward diffeomorphisms in deep nets indicates performance
Paper and Code

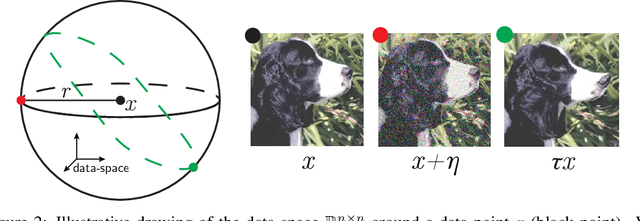


Understanding why deep nets can classify data in large dimensions remains a challenge. It has been proposed that they do so by becoming stable to diffeomorphisms, yet existing empirical measurements support that it is often not the case. We revisit this question by defining a maximum-entropy distribution on diffeomorphisms, that allows to study typical diffeomorphisms of a given norm. We confirm that stability toward diffeomorphisms does not strongly correlate to performance on four benchmark data sets of images. By contrast, we find that the stability toward diffeomorphisms relative to that of generic transformations $R_f$ correlates remarkably with the test error $\epsilon_t$. It is of order unity at initialization but decreases by several decades during training for state-of-the-art architectures. For CIFAR10 and 15 known architectures, we find $\epsilon_t\approx 0.2\sqrt{R_f}$, suggesting that obtaining a small $R_f$ is important to achieve good performance. We study how $R_f$ depends on the size of the training set and compare it to a simple model of invariant learning.