 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelation Transformer Network
Paper and Code

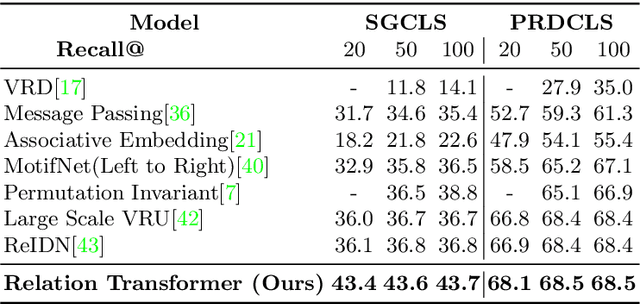
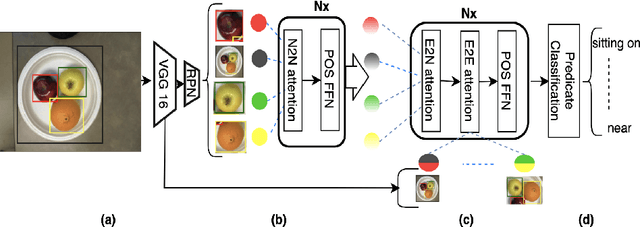
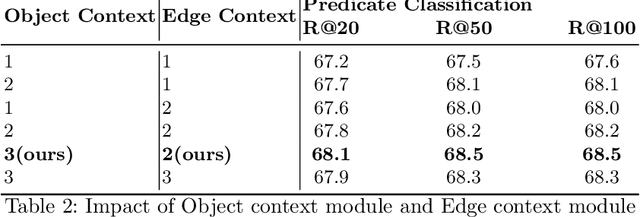
The identification of objects in an image, together with their mutual relationships, can lead to a deep understanding of image content. Despite all the recent advances in deep learning, in particular, the detection and labeling of visual object relationships remain a challenging task. In this work, we present the Relation Transformer Network, which is a customized transformer-based architecture that models complex object to object and edge to object interactions, by taking into account global context. Our hierarchical multi-head attention-based approach efficiently models and predicts dependencies between objects and their contextual relationships. In comparison to another state of the art approaches, we achieve an absolute mean 3.72% improvement in performance on the Visual Genome dataset.