 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning with Almost Sure Constraints
Paper and Code
Dec 09, 2021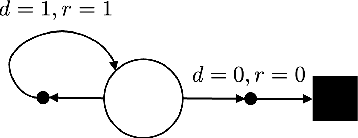
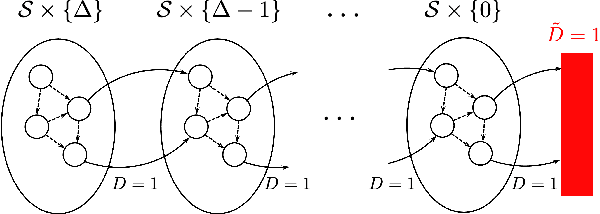
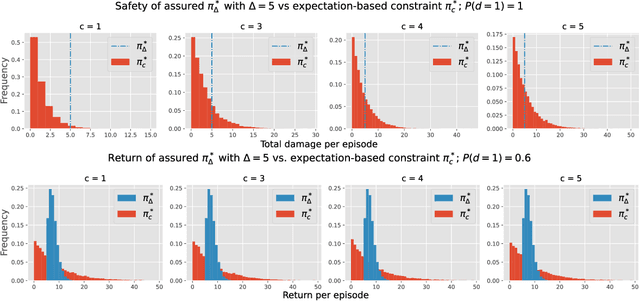
In this work we address the problem of finding feasible policies for Constrained Markov Decision Processes under probability one constraints. We argue that stationary policies are not sufficient for solving this problem, and that a rich class of policies can be found by endowing the controller with a scalar quantity, so called budget, that tracks how close the agent is to violating the constraint. We show that the minimal budget required to act safely can be obtained as the smallest fixed point of a Bellman-like operator, for which we analyze its convergence properties. We also show how to learn this quantity when the true kernel of the Markov decision process is not known, while providing sample-complexity bounds. The utility of knowing this minimal budget relies in that it can aid in the search of optimal or near-optimal policies by shrinking down the region of the state space the agent must navigate. Simulations illustrate the different nature of probability one constraints against the typically used constraints in expectation.