 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning from a Mixture of Interpretable Experts
Paper and Code
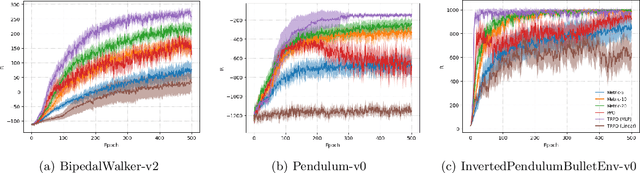
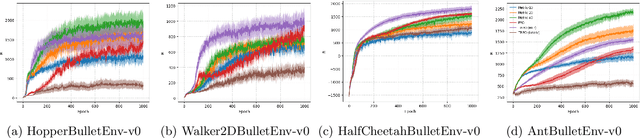
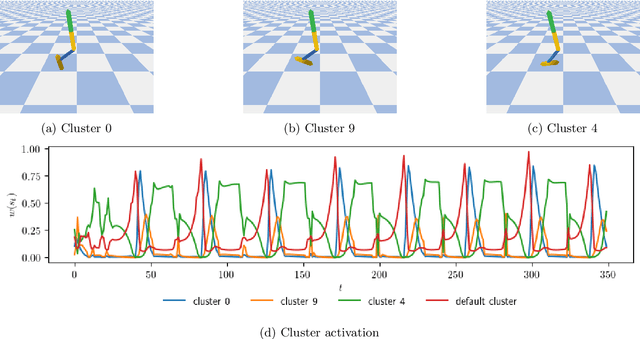
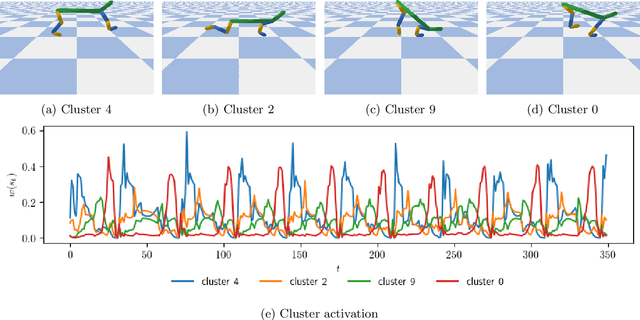
Reinforcement learning (RL) has demonstrated its ability to solve high dimensional tasks by leveraging non-linear function approximators. These successes however are mostly achieved by 'black-box' policies in simulated domains. When deploying RL to the real world, several concerns regarding the use of a 'black-box' policy might be raised. In an effort to make the policies learned by RL more transparent, we propose in this paper a policy iteration scheme that retains a complex function approximator for its internal value predictions but constrains the policy to have a concise, hierarchical, and human-readable structure, based on a mixture of interpretable experts. We show that our proposed algorithm can learn compelling policies on continuous action deep RL benchmarks, matching the performance of neural network based policies, but returns policies that are more amenable to human inspection than neural network or linear-in-feature policies.