 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReinforcement Learning as a Parsimonious Alternative to Prediction Cascades: A Case Study on Image Segmentation
Paper and Code
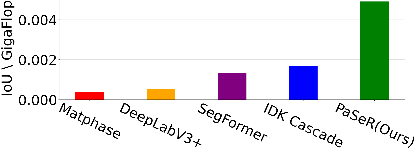

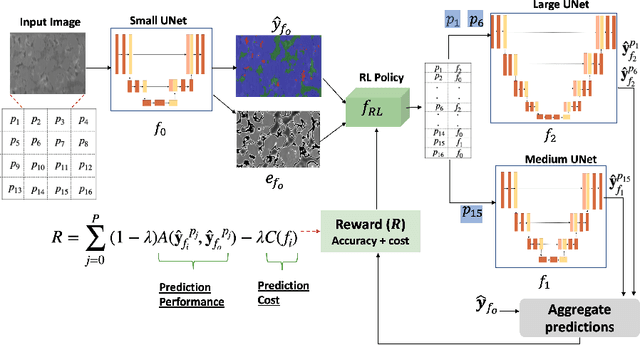

Deep learning architectures have achieved state-of-the-art (SOTA) performance on computer vision tasks such as object detection and image segmentation. This may be attributed to the use of over-parameterized, monolithic deep learning architectures executed on large datasets. Although such architectures lead to increased accuracy, this is usually accompanied by a large increase in computation and memory requirements during inference. While this is a non-issue in traditional machine learning pipelines, the recent confluence of machine learning and fields like the Internet of Things has rendered such large architectures infeasible for execution in low-resource settings. In such settings, previous efforts have proposed decision cascades where inputs are passed through models of increasing complexity until desired performance is achieved. However, we argue that cascaded prediction leads to increased computational cost due to wasteful intermediate computations. To address this, we propose PaSeR (Parsimonious Segmentation with Reinforcement Learning) a non-cascading, cost-aware learning pipeline as an alternative to cascaded architectures. Through experimental evaluation on real-world and standard datasets, we demonstrate that PaSeR achieves better accuracy while minimizing computational cost relative to cascaded models. Further, we introduce a new metric IoU/GigaFlop to evaluate the balance between cost and performance. On the real-world task of battery material phase segmentation, PaSeR yields a minimum performance improvement of 174% on the IoU/GigaFlop metric with respect to baselines. We also demonstrate PaSeR's adaptability to complementary models trained on a noisy MNIST dataset, where it achieved a minimum performance improvement on IoU/GigaFlop of 13.4% over SOTA models. Code and data are available at https://github.com/scailab/paser .