 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret Bounds for Safe Gaussian Process Bandit Optimization
Paper and Code
May 05, 2020


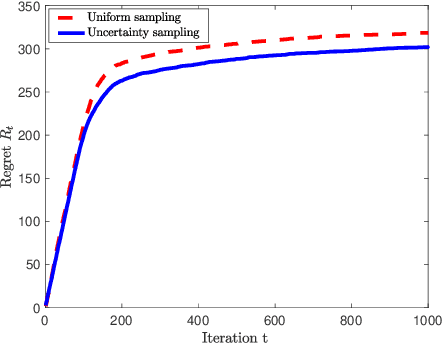
Many applications require a learner to make sequential decisions given uncertainty regarding both the system's payoff function and safety constraints. In safety-critical systems, it is paramount that the learner's actions do not violate the safety constraints at any stage of the learning process. In this paper, we study a stochastic bandit optimization problem where the unknown payoff and constraint functions are sampled from Gaussian Processes (GPs) first considered in [Srinivas et al., 2010]. We develop a safe variant of GP-UCB called SGP-UCB, with necessary modifications to respect safety constraints at every round. The algorithm has two distinct phases. The first phase seeks to estimate the set of safe actions in the decision set, while the second phase follows the GP-UCB decision rule. Our main contribution is to derive the first sub-linear regret bounds for this problem. We numerically compare SGP-UCB against existing safe Bayesian GP optimization algorithms.