Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRegret Bounds for Restless Markov Bandits
Paper and Code
Sep 12, 2012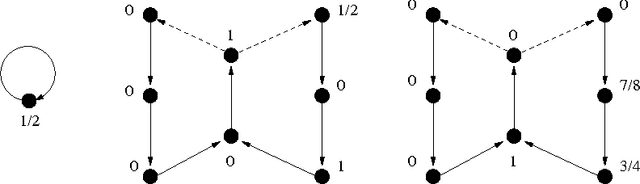
We consider the restless Markov bandit problem, in which the state of each arm evolves according to a Markov process independently of the learner's actions. We suggest an algorithm that after $T$ steps achieves $\tilde{O}(\sqrt{T})$ regret with respect to the best policy that knows the distributions of all arms. No assumptions on the Markov chains are made except that they are irreducible. In addition, we show that index-based policies are necessarily suboptimal for the considered problem.
* Proceedings of ALT, Lyon, France, LNCS 7568, pp.214-228, 2012 * In proceedings of The 23rd International Conference on Algorithmic
Learning Theory (ALT 2012)
View paper on