 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReframing Human-AI Collaboration for Generating Free-Text Explanations
Paper and Code

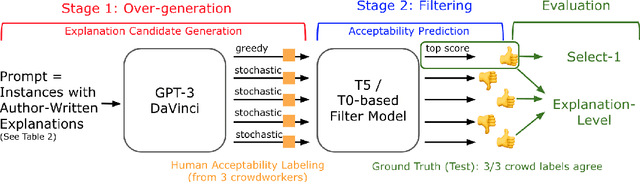


Large language models are increasingly capable of generating fluent-appearing text with relatively little task-specific supervision. But can these models accurately explain classification decisions? We consider the task of generating free-text explanations using a small number of human-written examples (i.e., in a few-shot manner). We find that (1) authoring higher-quality examples for prompting results in higher quality generations; and (2) surprisingly, in a head-to-head comparison, crowdworkers often prefer explanations generated by GPT-3 to crowdsourced human-written explanations contained within existing datasets. Crowdworker ratings also show, however, that while models produce factual, grammatical, and sufficient explanations, they have room to improve, e.g., along axes such as providing novel information and supporting the label. We create a pipeline that combines GPT-3 with a supervised filter that incorporates humans-in-the-loop via binary acceptability judgments. Despite significant subjectivity intrinsic to judging acceptability, our approach is able to consistently filter GPT-3 generated explanations deemed acceptable by humans.