 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReference Resolution and Context Change in Multimodal Situated Dialogue for Exploring Data Visualizations
Paper and Code
Sep 06, 2022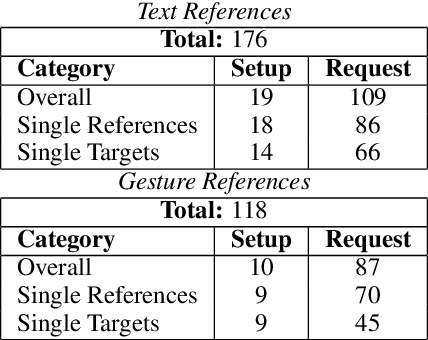
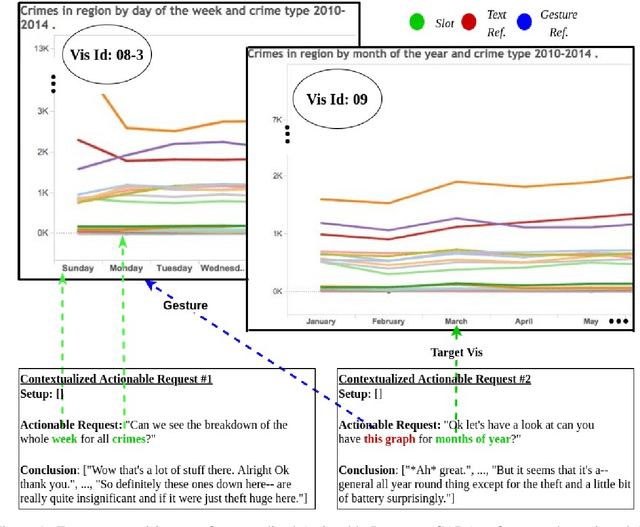
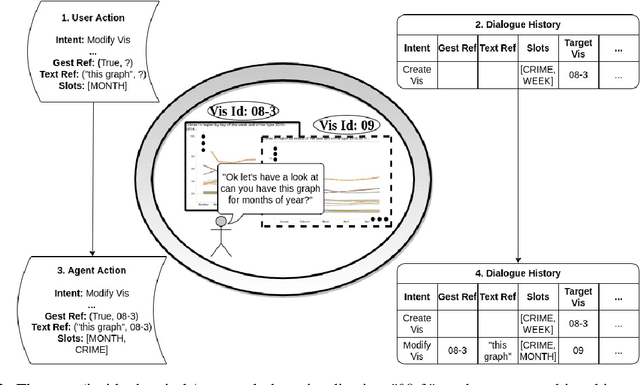
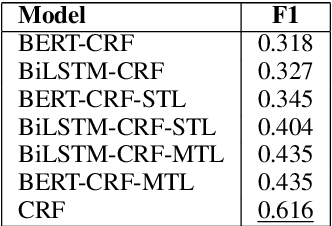
Reference resolution, which aims to identify entities being referred to by a speaker, is more complex in real world settings: new referents may be created by processes the agents engage in and/or be salient only because they belong to the shared physical setting. Our focus is on resolving references to visualizations on a large screen display in multimodal dialogue; crucially, reference resolution is directly involved in the process of creating new visualizations. We describe our annotations for user references to visualizations appearing on a large screen via language and hand gesture and also new entity establishment, which results from executing the user request to create a new visualization. We also describe our reference resolution pipeline which relies on an information-state architecture to maintain dialogue context. We report results on detecting and resolving references, effectiveness of contextual information on the model, and under-specified requests for creating visualizations. We also experiment with conventional CRF and deep learning / transformer models (BiLSTM-CRF and BERT-CRF) for tagging references in user utterance text. Our results show that transfer learning significantly boost performance of the deep learning methods, although CRF still out-performs them, suggesting that conventional methods may generalize better for low resource data.