 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRED-DOT: Multimodal Fact-checking via Relevant Evidence Detection
Paper and Code
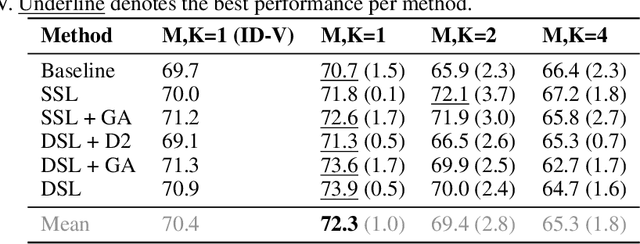

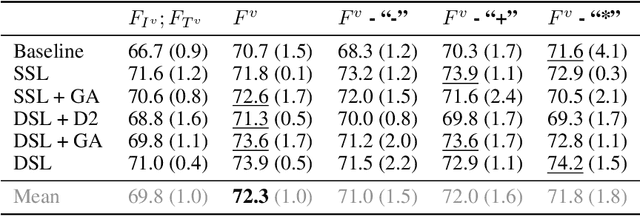
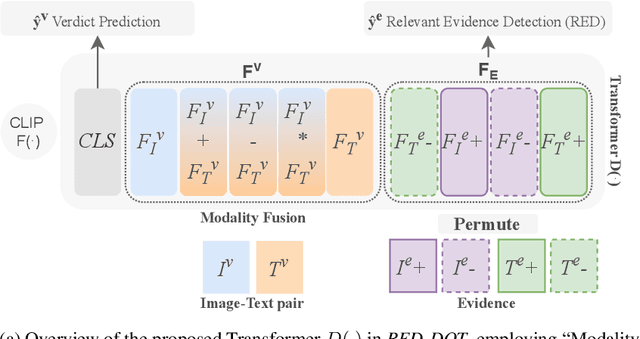
Online misinformation is often multimodal in nature, i.e., it is caused by misleading associations between texts and accompanying images. To support the fact-checking process, researchers have been recently developing automatic multimodal methods that gather and analyze external information, evidence, related to the image-text pairs under examination. However, prior works assumed all collected evidence to be relevant. In this study, we introduce a "Relevant Evidence Detection" (RED) module to discern whether each piece of evidence is relevant, to support or refute the claim. Specifically, we develop the "Relevant Evidence Detection Directed Transformer" (RED-DOT) and explore multiple architectural variants (e.g., single or dual-stage) and mechanisms (e.g., "guided attention"). Extensive ablation and comparative experiments demonstrate that RED-DOT achieves significant improvements over the state-of-the-art on the VERITE benchmark by up to 28.5%. Furthermore, our evidence re-ranking and element-wise modality fusion led to RED-DOT achieving competitive and even improved performance on NewsCLIPings+, without the need for numerous evidence or multiple backbone encoders. Finally, our qualitative analysis demonstrates that the proposed "guided attention" module has the potential to enhance the architecture's interpretability. We release our code at: https://github.com/stevejpapad/relevant-evidence-detection