 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecurrent Self-Supervised Video Denoising with Denser Receptive Field
Paper and Code


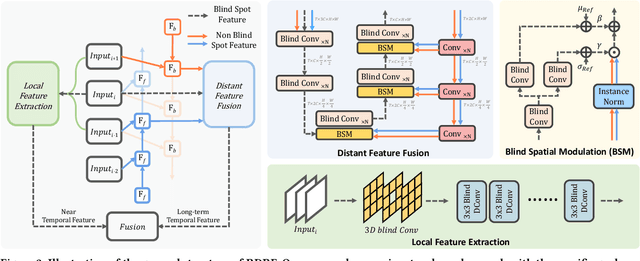

Self-supervised video denoising has seen decent progress through the use of blind spot networks. However, under their blind spot constraints, previous self-supervised video denoising methods suffer from significant information loss and texture destruction in either the whole reference frame or neighbor frames, due to their inadequate consideration of the receptive field. Moreover, the limited number of available neighbor frames in previous methods leads to the discarding of distant temporal information. Nonetheless, simply adopting existing recurrent frameworks does not work, since they easily break the constraints on the receptive field imposed by self-supervision. In this paper, we propose RDRF for self-supervised video denoising, which not only fully exploits both the reference and neighbor frames with a denser receptive field, but also better leverages the temporal information from both local and distant neighbor features. First, towards a comprehensive utilization of information from both reference and neighbor frames, RDRF realizes a denser receptive field by taking more neighbor pixels along the spatial and temporal dimensions. Second, it features a self-supervised recurrent video denoising framework, which concurrently integrates distant and near-neighbor temporal features. This enables long-term bidirectional information aggregation, while mitigating error accumulation in the plain recurrent framework. Our method exhibits superior performance on both synthetic and real video denoising datasets. Codes will be available at https://github.com/Wang-XIaoDingdd/RDRF.