 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRealistic Deep Learning May Not Fit Benignly
Paper and Code
Jun 01, 2022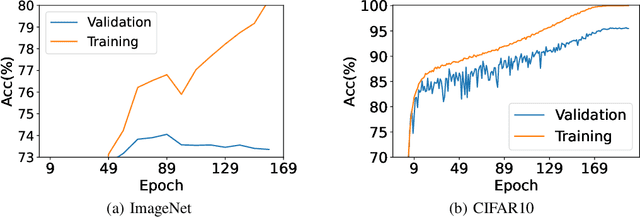
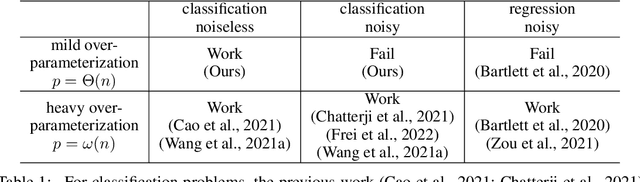
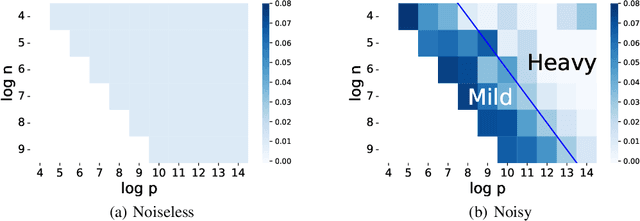
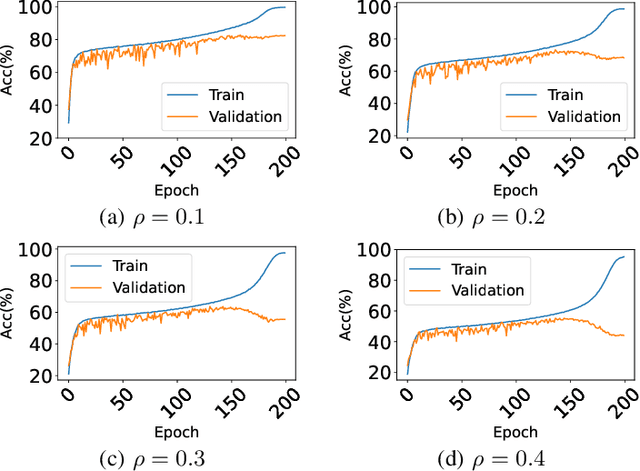
Studies on benign overfitting provide insights for the success of overparameterized deep learning models. In this work, we examine the benign overfitting phenomena in real-world settings. We found that for tasks such as training a ResNet model on ImageNet dataset, the model does not fit benignly. To understand why benign overfitting fails in the ImageNet experiment, we analyze previous benign overfitting models under a more restrictive setup where the number of parameters is not significantly larger than the number of data points. Under this mild overparameterization setup, our analysis identifies a phase change: unlike in the heavy overparameterization setting, benign overfitting can now fail in the presence of label noise. Our study explains our empirical observations, and naturally leads to a simple technique known as self-training that can boost the model's generalization performances. Furthermore, our work highlights the importance of understanding implicit bias in underfitting regimes as a future direction.