 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Anomalous Behavior Detection and Localization in Crowded Scenes
Paper and Code
Jan 02, 2016


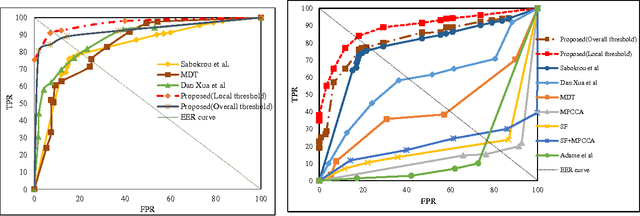
In this paper, we propose an accurate and real-time anomaly detection and localization in crowded scenes, and two descriptors for representing anomalous behavior in video are proposed. We consider a video as being a set of cubic patches. Based on the low likelihood of an anomaly occurrence, and the redundancy of structures in normal patches in videos, two (global and local) views are considered for modeling the video. Our algorithm has two components, for (1) representing the patches using local and global descriptors, and for (2) modeling the training patches using a new representation. We have two Gaussian models for all training patches respect to global and local descriptors. The local and global features are based on structure similarity between adjacent patches and the features that are learned in an unsupervised way. We propose a fusion strategy to combine the two descriptors as the output of our system. Experimental results show that our algorithm performs like a state-of-the-art method on several standard datasets, but even is more time-efficient.