 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRead the Room: Adapting a Robot's Voice to Ambient and Social Contexts
Paper and Code

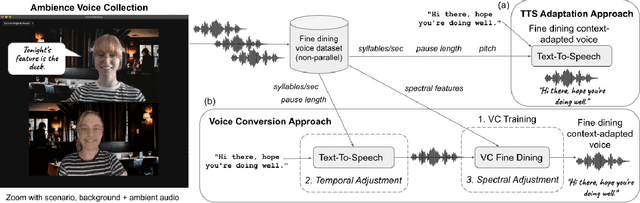
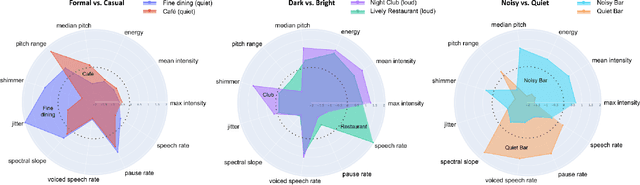

Adapting one's voice to different ambient environments and social interactions is required for human social interaction. In robotics, the ability to recognize speech in noisy and quiet environments has received significant attention, but considering ambient cues in the production of social speech features has been little explored. Our research aims to modify a robot's speech to maximize acceptability in various social and acoustic contexts, starting with a use case for service robots in varying restaurants. We created an original dataset collected over Zoom with participants conversing in scripted and unscripted tasks given 7 different ambient sounds and background images. Voice conversion methods, in addition to altered Text-to-Speech that matched ambient specific data, were used for speech synthesis tasks. We conducted a subjective perception study that showed humans prefer synthetic speech that matches ambience and social context, ultimately preferring more human-like voices. This work provides three solutions to ambient and socially appropriate synthetic voices: (1) a novel protocol to collect real contextual audio voice data, (2) tools and directions to manipulate robot speech for appropriate social and ambient specific interactions, and (3) insight into voice conversion's role in flexibly altering robot speech to match different ambient environments.