 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRe^2TAL: Rewiring Pretrained Video Backbones for Reversible Temporal Action Localization
Paper and Code
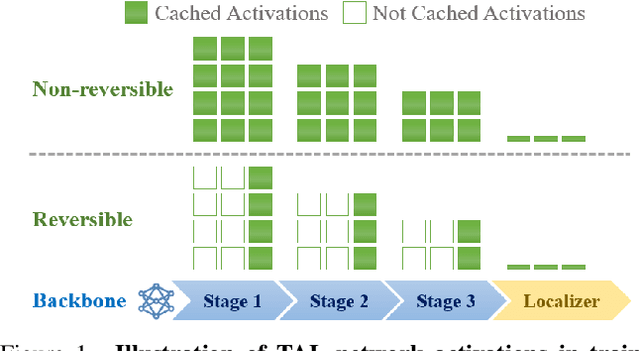
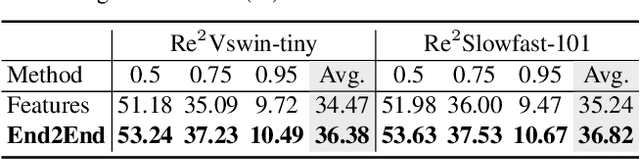


Temporal action localization (TAL) requires long-form reasoning to predict actions of various lengths and complex content. Given limited GPU memory, training TAL end-to-end on such long-form videos (i.e., from videos to predictions) is a significant challenge. Most methods can only train on pre-extracted features without optimizing them for the localization problem, consequently limiting localization performance. In this work, to extend the potential in TAL networks, we propose a novel end-to-end method Re2TAL, which rewires pretrained video backbones for reversible TAL. Re2TAL builds a backbone with reversible modules, where the input can be recovered from the output such that the bulky intermediate activations can be cleared from memory during training. Instead of designing one single type of reversible module, we propose a network rewiring mechanism, to transform any module with a residual connection to a reversible module without changing any parameters. This provides two benefits: (1) a large variety of reversible networks are easily obtained from existing and even future model designs, and (2) the reversible models require much less training effort as they reuse the pre-trained parameters of their original non-reversible versions. Re2TAL reaches 37.01% average mAP, a new state-of-the-art record on ActivityNet-v1.3, and mAP 64.9% at tIoU=0.5 on THUMOS-14 without using optimal flow.