 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRanking in Contextual Multi-Armed Bandits
Paper and Code
Jun 30, 2022
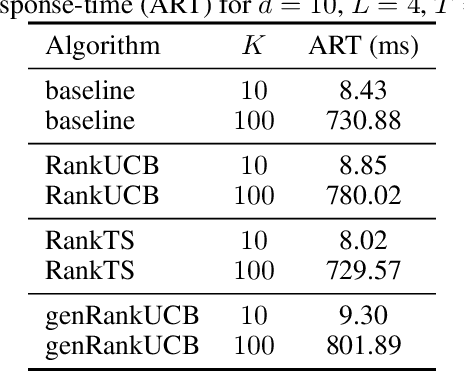
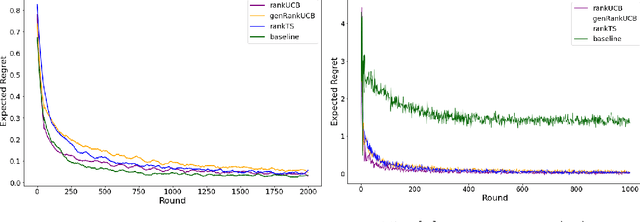
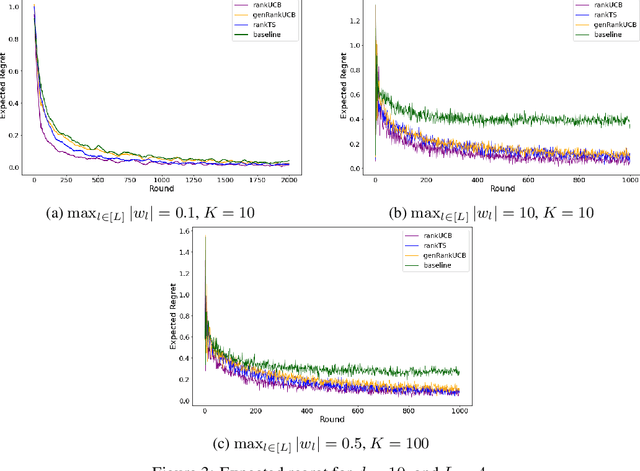
We study a ranking problem in the contextual multi-armed bandit setting. A learning agent selects an ordered list of items at each time step and observes stochastic outcomes for each position. In online recommendation systems, showing an ordered list of the most attractive items would not be the best choice since both position and item dependencies result in a complicated reward function. A very naive example is the lack of diversity when all the most attractive items are from the same category. We model position and item dependencies in the ordered list and design UCB and Thompson Sampling type algorithms for this problem. We prove that the regret bound over $T$ rounds and $L$ positions is $\Tilde{O}(L\sqrt{d T})$, which has the same order as the previous works with respect to $T$ and only increases linearly with $L$. Our work generalizes existing studies in several directions, including position dependencies where position discount is a particular case, and proposes a more general contextual bandit model.