Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Algorithms for Large scale SVMs
Paper and Code
Sep 19, 2009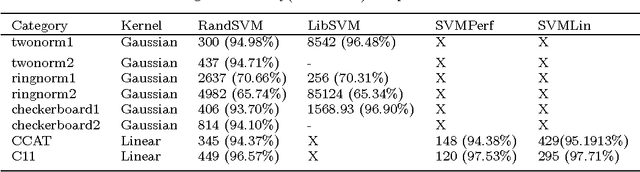

We propose a randomized algorithm for training Support vector machines(SVMs) on large datasets. By using ideas from Random projections we show that the combinatorial dimension of SVMs is $O({log} n)$ with high probability. This estimate of combinatorial dimension is used to derive an iterative algorithm, called RandSVM, which at each step calls an existing solver to train SVMs on a randomly chosen subset of size $O({log} n)$. The algorithm has probabilistic guarantees and is capable of training SVMs with Kernels for both classification and regression problems. Experiments done on synthetic and real life data sets demonstrate that the algorithm scales up existing SVM learners, without loss of accuracy.
* 17 pages, Submitted to Machine Learning journal (October 2008) -
under revision
View paper on