Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Projections for Linear Support Vector Machines
Paper and Code
Apr 17, 2014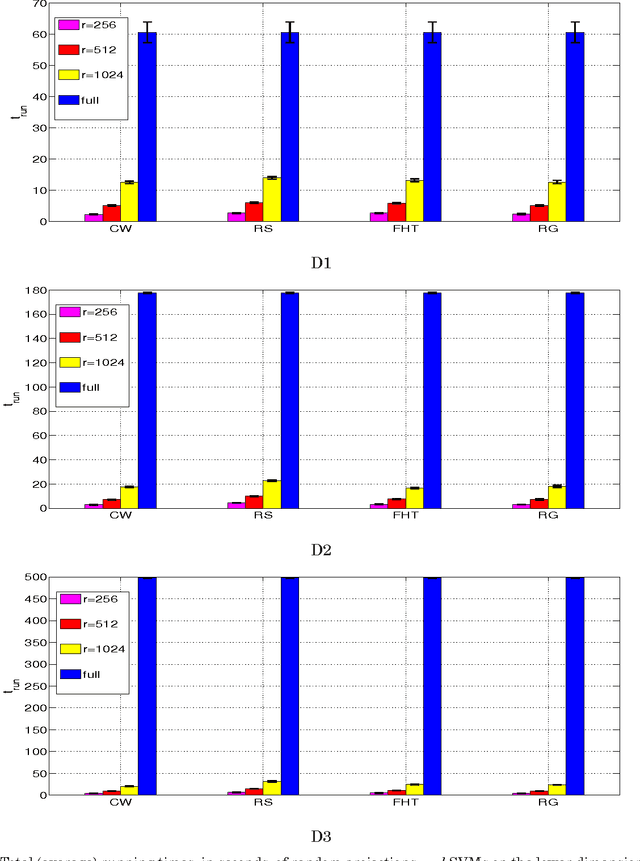
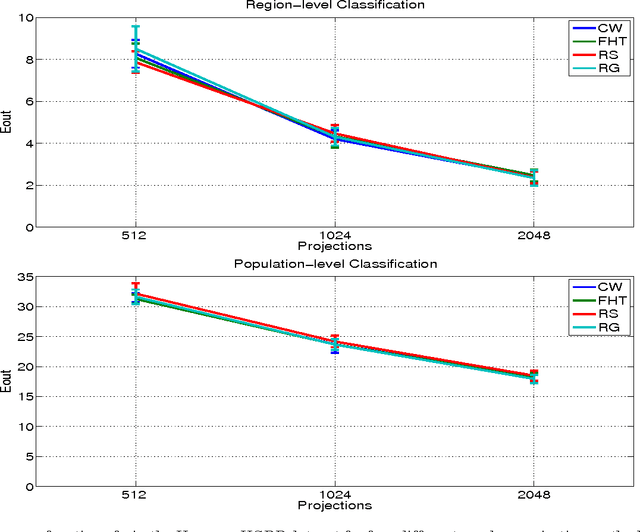
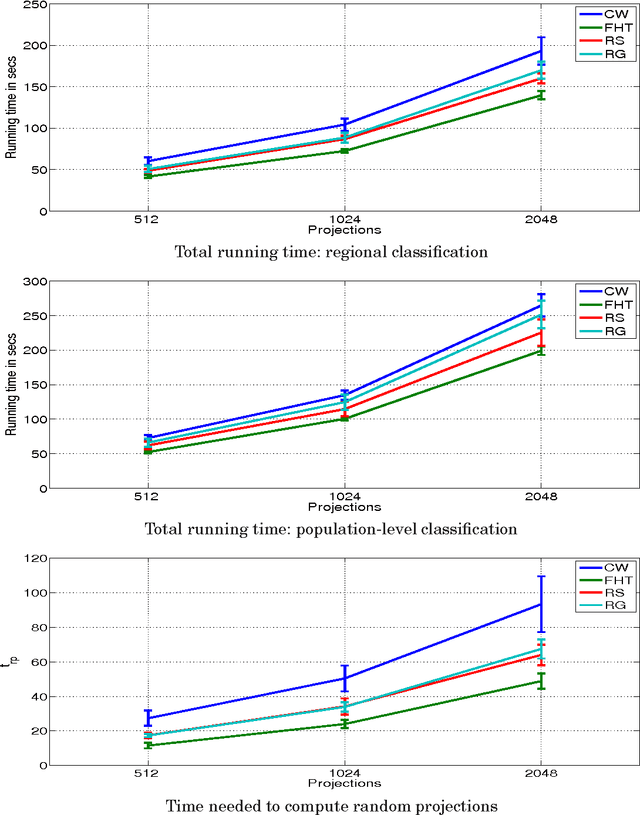
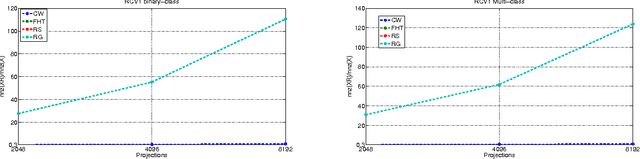
Let X be a data matrix of rank \rho, whose rows represent n points in d-dimensional space. The linear support vector machine constructs a hyperplane separator that maximizes the 1-norm soft margin. We develop a new oblivious dimension reduction technique which is precomputed and can be applied to any input matrix X. We prove that, with high probability, the margin and minimum enclosing ball in the feature space are preserved to within \epsilon-relative error, ensuring comparable generalization as in the original space in the case of classification. For regression, we show that the margin is preserved to \epsilon-relative error with high probability. We present extensive experiments with real and synthetic data to support our theory.
* To appear in ACM TKDD, 2014. Shorter version appeared at AISTATS 2013
View paper on