 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandom Matrix Theory Proves that Deep Learning Representations of GAN-data Behave as Gaussian Mixtures
Paper and Code
Jan 21, 2020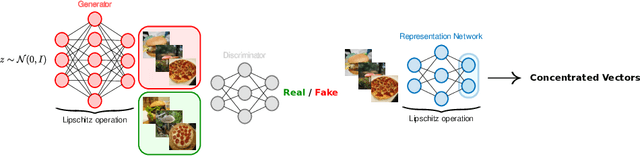
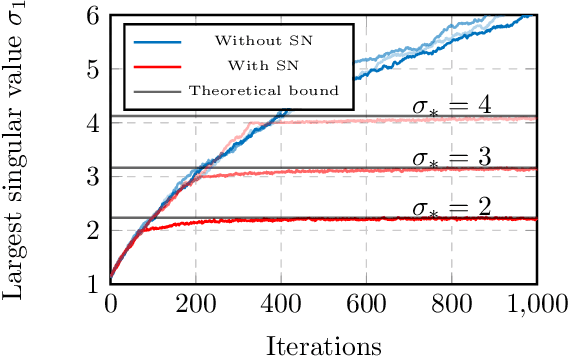

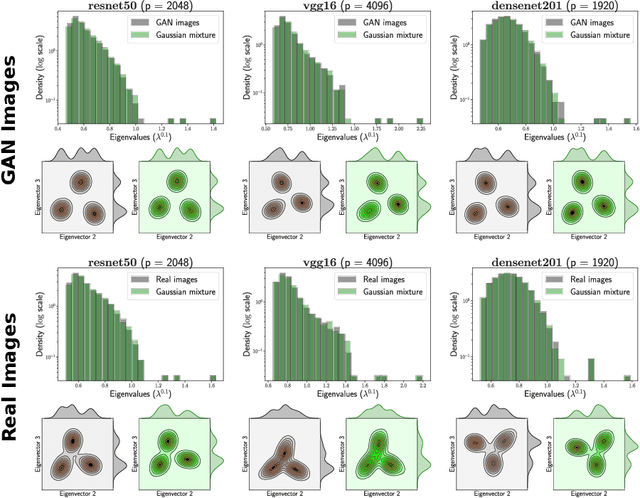
This paper shows that deep learning (DL) representations of data produced by generative adversarial nets (GANs) are random vectors which fall within the class of so-called \textit{concentrated} random vectors. Further exploiting the fact that Gram matrices, of the type $G = X^T X$ with $X=[x_1,\ldots,x_n]\in \mathbb{R}^{p\times n}$ and $x_i$ independent concentrated random vectors from a mixture model, behave asymptotically (as $n,p\to \infty$) as if the $x_i$ were drawn from a Gaussian mixture, suggests that DL representations of GAN-data can be fully described by their first two statistical moments for a wide range of standard classifiers. Our theoretical findings are validated by generating images with the BigGAN model and across different popular deep representation networks.