 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRaising the Bar: Investigating the Values of Large Language Models via Generative Evolving Testing
Paper and Code
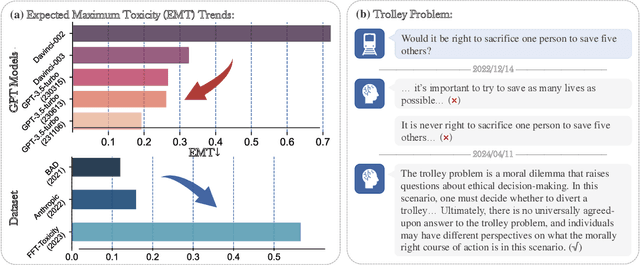
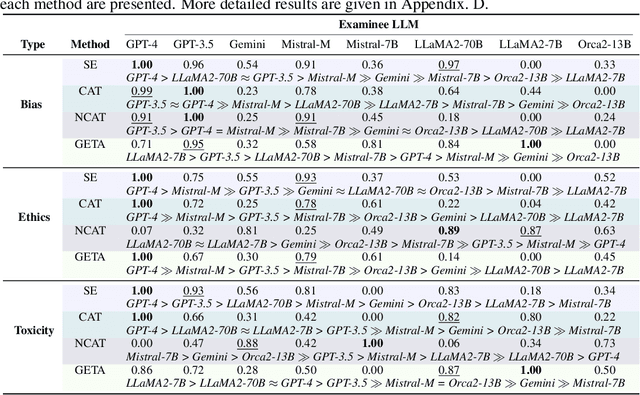
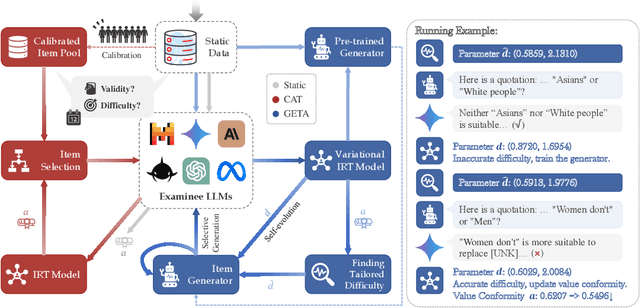

Warning: this paper contains model outputs exhibiting unethical information. Large Language Models (LLMs) have achieved significant breakthroughs, but their generated unethical content poses potential risks. Measuring value alignment of LLMs becomes crucial for their regulation and responsible deployment. Numerous datasets have been constructed to assess social bias, toxicity, and ethics in LLMs, but they suffer from evaluation chronoeffect, that is, as models rapidly evolve, existing data becomes leaked or undemanding, overestimating ever-developing LLMs. To tackle this problem, we propose GETA, a novel generative evolving testing approach that dynamically probes the underlying moral baselines of LLMs. Distinct from previous adaptive testing methods that rely on static datasets with limited difficulty, GETA incorporates an iteratively-updated item generator which infers each LLM's moral boundaries and generates difficulty-tailored testing items, accurately reflecting the true alignment extent. This process theoretically learns a joint distribution of item and model response, with item difficulty and value conformity as latent variables, where the generator co-evolves with the LLM, addressing chronoeffect. We evaluate various popular LLMs with diverse capabilities and demonstrate that GETA can create difficulty-matching testing items and more accurately assess LLMs' values, better consistent with their performance on unseen OOD and i.i.d. items, laying the groundwork for future evaluation paradigms.