 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeR-Tuning: Regularized Prompt Tuning in Open-Set Scenarios
Paper and Code
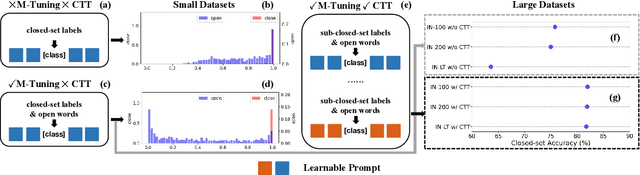
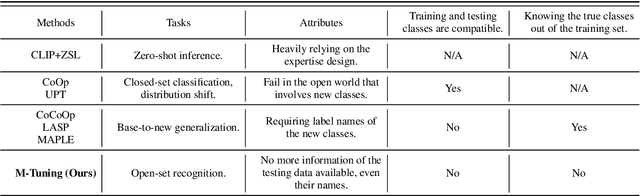
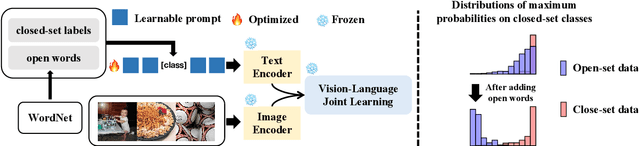
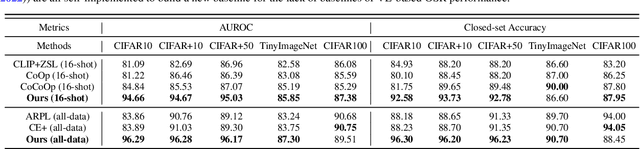
In realistic open-set scenarios where labels of a part of testing data are totally unknown, current prompt methods on vision-language (VL) models always predict the unknown classes as the downstream training classes. The exhibited label bias causes difficulty in the open set recognition (OSR), by which an image should be correctly predicted as one of the known classes or the unknown one. To learn prompts in open-set scenarios, we propose the Regularized prompt Tuning (R-Tuning) to mitigate the label bias. It introduces open words from the WordNet to extend the range of words forming the prompt texts from only closed-set label words to more. Thus, prompts are tuned in a simulated open-set scenario. Besides, inspired by the observation that classifying directly on large datasets causes a much higher false positive rate than on small datasets, we propose the Combinatorial Tuning and Testing (CTT) strategy for improving performance. CTT decomposes R-Tuning on large datasets as multiple independent group-wise tuning on fewer classes, then makes comprehensive predictions by selecting the optimal sub-prompt. For fair comparisons, we construct new baselines for OSR based on VL models, especially for prompt methods. Our method achieves the best results on datasets with various scales. Extensive ablation studies validate the effectiveness of our method.