 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuery Significance in Databases via Randomizations
Paper and Code
Jun 30, 2009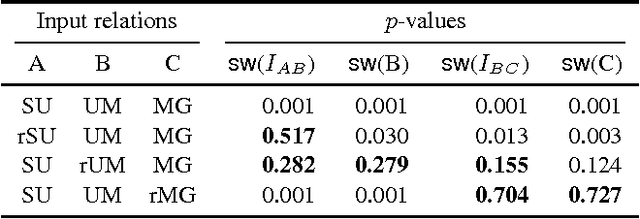
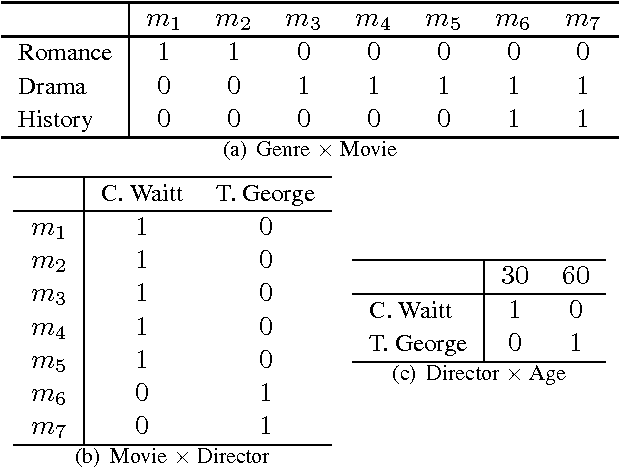
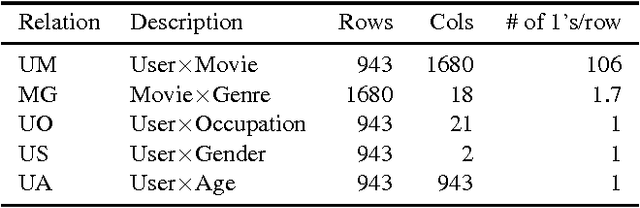
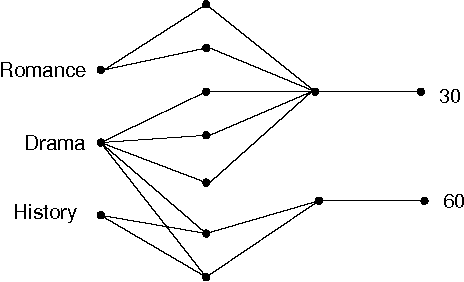
Many sorts of structured data are commonly stored in a multi-relational format of interrelated tables. Under this relational model, exploratory data analysis can be done by using relational queries. As an example, in the Internet Movie Database (IMDb) a query can be used to check whether the average rank of action movies is higher than the average rank of drama movies. We consider the problem of assessing whether the results returned by such a query are statistically significant or just a random artifact of the structure in the data. Our approach is based on randomizing the tables occurring in the queries and repeating the original query on the randomized tables. It turns out that there is no unique way of randomizing in multi-relational data. We propose several randomization techniques, study their properties, and show how to find out which queries or hypotheses about our data result in statistically significant information. We give results on real and generated data and show how the significance of some queries vary between different randomizations.