 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantizing data for distributed learning
Paper and Code
Dec 14, 2020
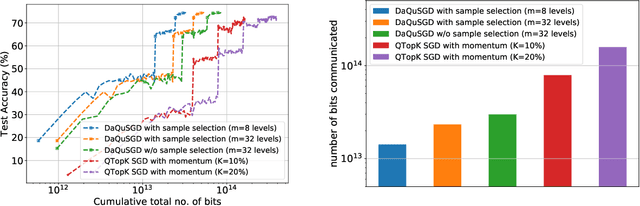
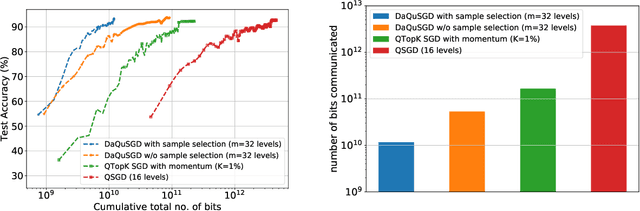
We consider machine learning applications that train a model by leveraging data distributed over a network, where communication constraints can create a performance bottleneck. A number of recent approaches are proposing to overcome this bottleneck through compression of gradient updates. However, as models become larger, so does the size of the gradient updates. In this paper, we propose an alternate approach, that quantizes data instead of gradients, and can support learning over applications where the size of gradient updates is prohibitive. Our approach combines aspects of: (1) sample selection; (2) dataset quantization; and (3) gradient compensation. We analyze the convergence of the proposed approach for smooth convex and non-convex objective functions and show that we can achieve order optimal convergence rates with communication that mostly depends on the data rather than the model (gradient) dimension. We use our proposed algorithm to train ResNet models on the CIFAR-10 and ImageNet datasets, and show that we can achieve an order of magnitude savings over gradient compression methods.