 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantized Sparse Weight Decomposition for Neural Network Compression
Paper and Code
Jul 22, 2022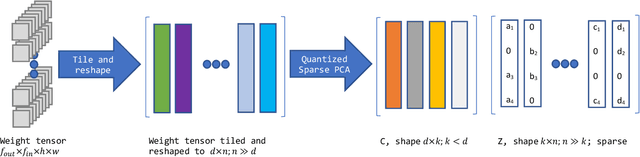
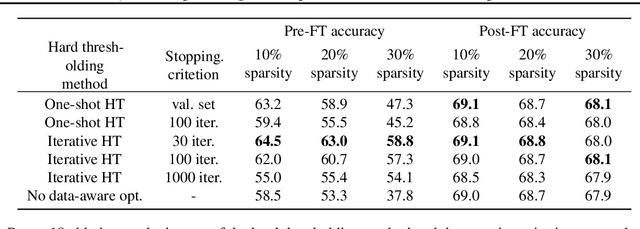
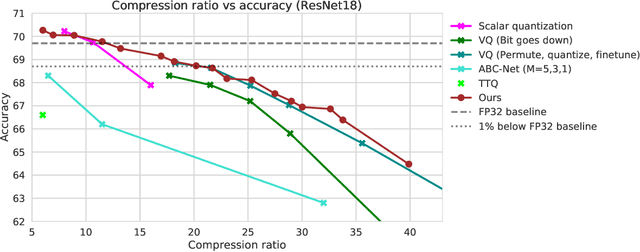
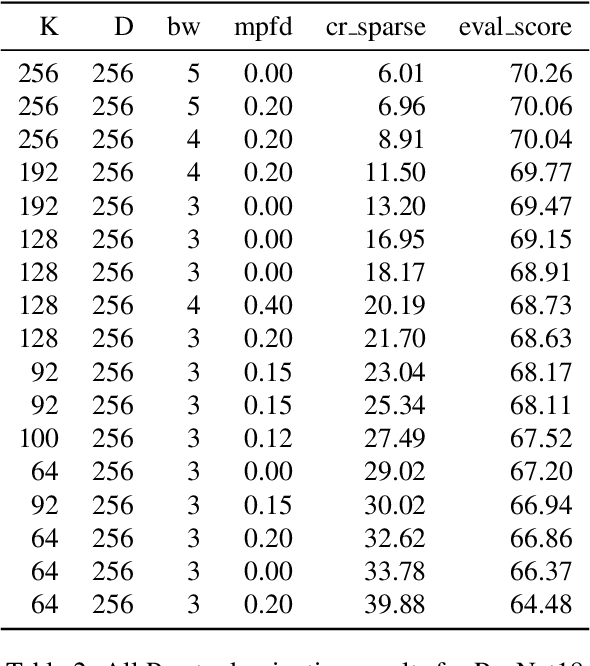
In this paper, we introduce a novel method of neural network weight compression. In our method, we store weight tensors as sparse, quantized matrix factors, whose product is computed on the fly during inference to generate the target model's weights. We use projected gradient descent methods to find quantized and sparse factorization of the weight tensors. We show that this approach can be seen as a unification of weight SVD, vector quantization, and sparse PCA. Combined with end-to-end fine-tuning our method exceeds or is on par with previous state-of-the-art methods in terms of the trade-off between accuracy and model size. Our method is applicable to both moderate compression regimes, unlike vector quantization, and extreme compression regimes.