Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Complexity of Standard Benchmarking Datasets for Long-Term Human Trajectory Prediction
Paper and Code
May 28, 2020
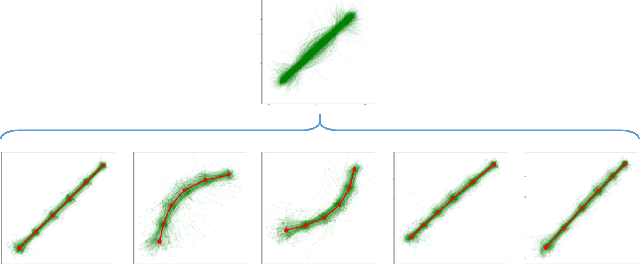
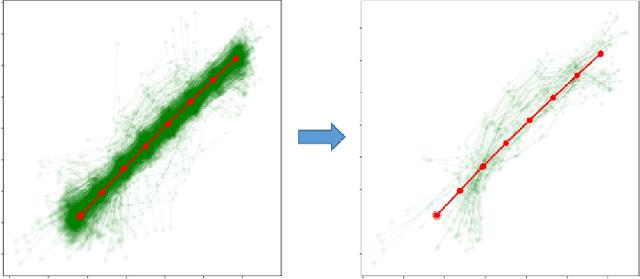
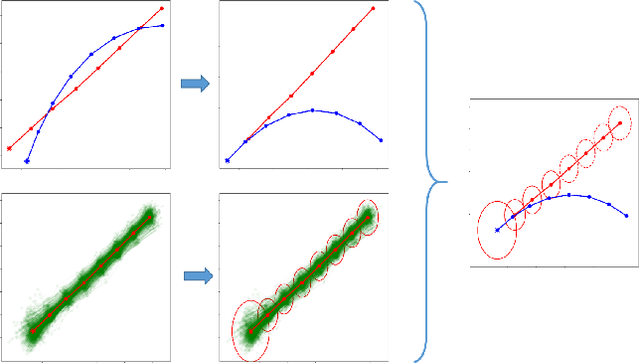
Methods to quantify the complexity of trajectory datasets are still a missing piece in benchmarking human trajectory prediction models. In order to gain a better understanding of the complexity of trajectory datasets, an approach for deriving complexity scores from a prototype-based dataset representation is proposed. The dataset representation is obtained by first employing a non-trivial spatial sequence alignment, which enables a following learning vector quantization (LVQ) stage. A large-scale complexity analysis is conducted on several human trajectory prediction benchmarking datasets, followed by a brief discussion on indications for human trajectory prediction and benchmarking.
* Submitted to RA-L Special Issue on Long-Term Human Motion Prediction
View paper on