 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying the Burden of Exploration and the Unfairness of Free Riding
Paper and Code
Oct 20, 2018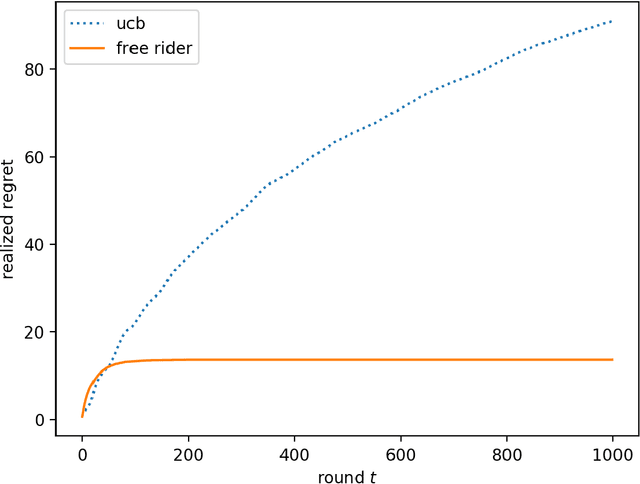
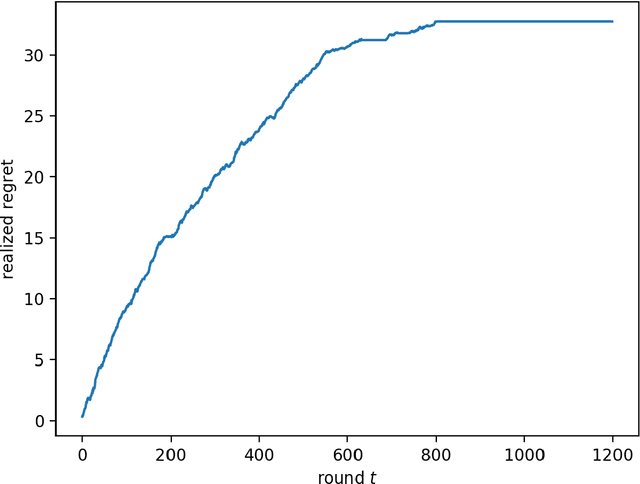
We consider the multi-armed bandit setting with a twist. Rather than having just one decision maker deciding which arm to pull in each round, we have $n$ different decision makers (agents). In the simple stochastic setting we show that one of the agents (called the free rider), who has access to the history of other agents playing some zero regret algorithm can achieve just $O(1)$ regret, as opposed to the regret lower bound of $\Omega (\log T)$ when one decision maker is playing in isolation. In the linear contextual setting, we show that if the other agents play a particular, popular zero regret algorithm (UCB), then the free rider can again achieve $O(1)$ regret. In order to prove this result, we give a deterministic lower bound on the number of times each suboptimal arm must be pulled in UCB. In contrast, we show that the free-rider cannot beat the standard single-player regret bounds in certain partial information settings.