 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantifying Exposure Bias for Neural Language Generation
Paper and Code

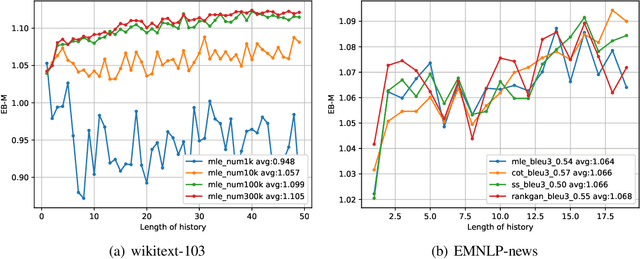


The exposure bias problem refers to the training-inference discrepancy caused by teacher forcing in maximum likelihood estimation (MLE) training for recurrent neural network language models (RNNLM). It has been regarded as a central problem for natural language generation (NLG) model training. Although a lot of algorithms have been proposed to avoid teacher forcing and therefore to remove exposure bias, there is little work showing how serious the exposure bias problem is. In this work, starting from the definition of exposure bias, we propose two simple and intuitive approaches to quantify exposure bias for MLE-trained language models. Experiments are conducted on both synthetic and real data-sets. Surprisingly, our results indicate that either exposure bias is trivial (i.e. indistinguishable from the mismatch between model and data distribution), or is not as significant as it is presumed to be (with a measured performance gap of 3%). With this work, we suggest re-evaluating the viewpoint that teacher forcing or exposure bias is a major drawback of MLE training.