 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantification before Selection: Active Dynamics Preference for Robust Reinforcement Learning
Paper and Code
Sep 28, 2022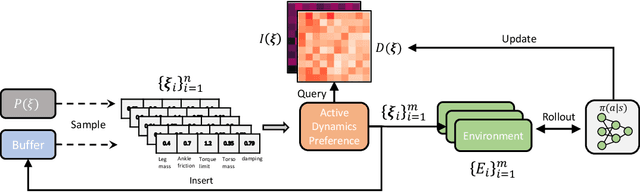
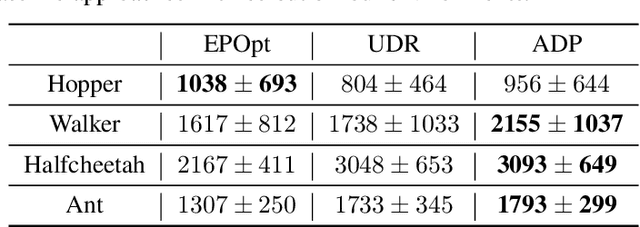


Training a robust policy is critical for policy deployment in real-world systems or dealing with unknown dynamics mismatch in different dynamic systems. Domain Randomization~(DR) is a simple and elegant approach that trains a conservative policy to counter different dynamic systems without expert knowledge about the target system parameters. However, existing works reveal that the policy trained through DR tends to be over-conservative and performs poorly in target domains. Our key insight is that dynamic systems with different parameters provide different levels of difficulty for the policy, and the difficulty of behaving well in a system is constantly changing due to the evolution of the policy. If we can actively sample the systems with proper difficulty for the policy on the fly, it will stabilize the training process and prevent the policy from becoming over-conservative or over-optimistic. To operationalize this idea, we introduce Active Dynamics Preference~(ADP), which quantifies the informativeness and density of sampled system parameters. ADP actively selects system parameters with high informativeness and low density. We validate our approach in four robotic locomotion tasks with various discrepancies between the training and testing environments. Extensive results demonstrate that our approach has superior robustness for system inconsistency compared to several baselines.