 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQualitative System Identification from Imperfect Data
Paper and Code
Oct 31, 2011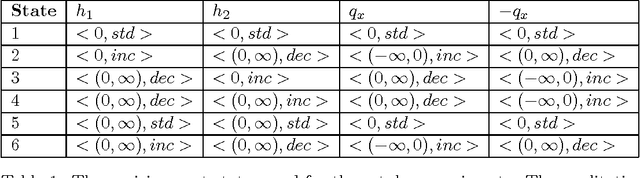
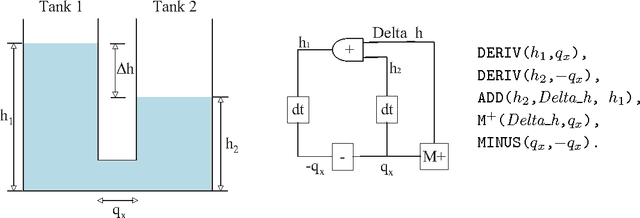

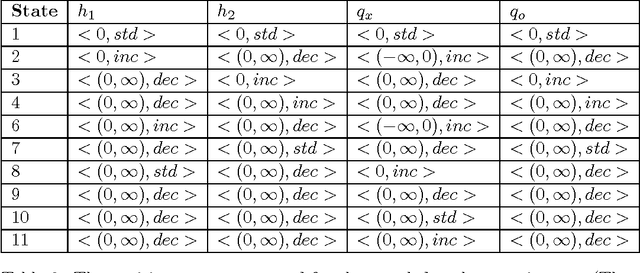
Experience in the physical sciences suggests that the only realistic means of understanding complex systems is through the use of mathematical models. Typically, this has come to mean the identification of quantitative models expressed as differential equations. Quantitative modelling works best when the structure of the model (i.e., the form of the equations) is known; and the primary concern is one of estimating the values of the parameters in the model. For complex biological systems, the model-structure is rarely known and the modeler has to deal with both model-identification and parameter-estimation. In this paper we are concerned with providing automated assistance to the first of these problems. Specifically, we examine the identification by machine of the structural relationships between experimentally observed variables. These relationship will be expressed in the form of qualitative abstractions of a quantitative model. Such qualitative models may not only provide clues to the precise quantitative model, but also assist in understanding the essence of that model. Our position in this paper is that background knowledge incorporating system modelling principles can be used to constrain effectively the set of good qualitative models. Utilising the model-identification framework provided by Inductive Logic Programming (ILP) we present empirical support for this position using a series of increasingly complex artificial datasets. The results are obtained with qualitative and quantitative data subject to varying amounts of noise and different degrees of sparsity. The results also point to the presence of a set of qualitative states, which we term kernel subsets, that may be necessary for a qualitative model-learner to learn correct models. We demonstrate scalability of the method to biological system modelling by identification of the glycolysis metabolic pathway from data.