Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuadratic models for understanding neural network dynamics
Paper and Code
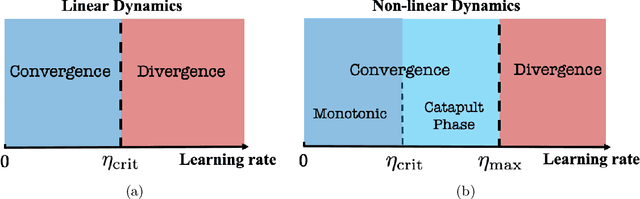
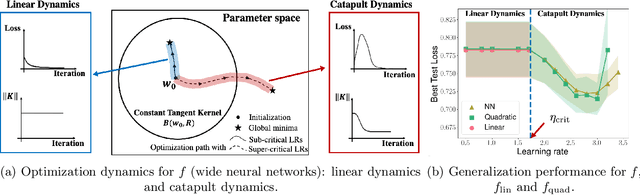
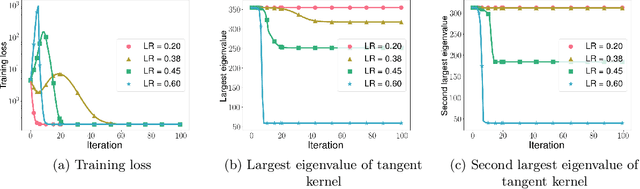
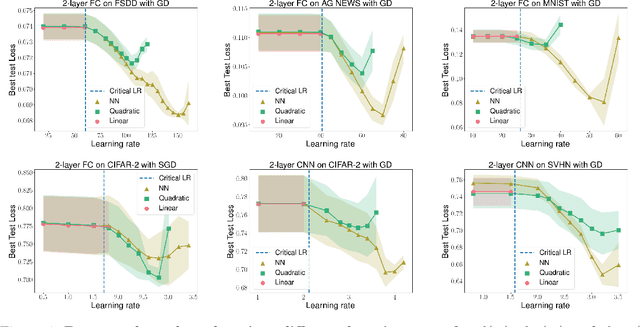
In this work, we propose using a quadratic model as a tool for understanding properties of wide neural networks in both optimization and generalization. We show analytically that certain deep learning phenomena such as the "catapult phase" from [Lewkowycz et al. 2020], which cannot be captured by linear models, are manifested in the quadratic model for shallow ReLU networks. Furthermore, our empirical results indicate that the behaviour of quadratic models parallels that of neural networks in generalization, especially in the large learning rate regime. We expect that quadratic models will serve as a useful tool for analysis of neural networks.
View paper on
 OpenReview
OpenReview