 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQS-Craft: Learning to Quantize, Scrabble and Craft for Conditional Human Motion Animation
Paper and Code
Mar 22, 2022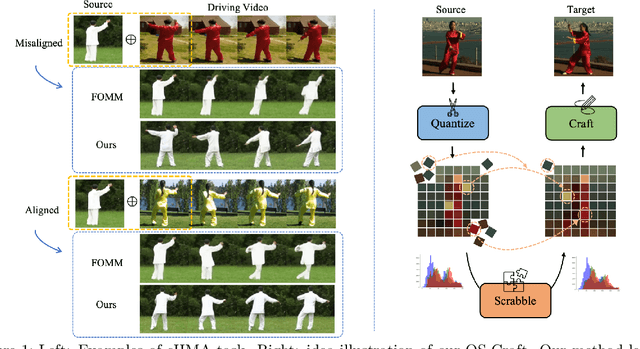
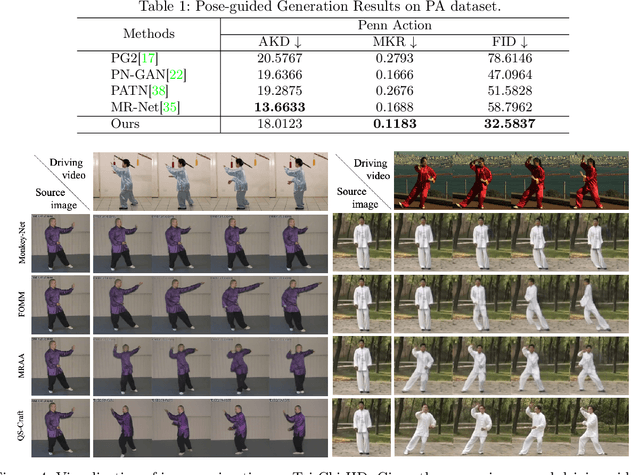
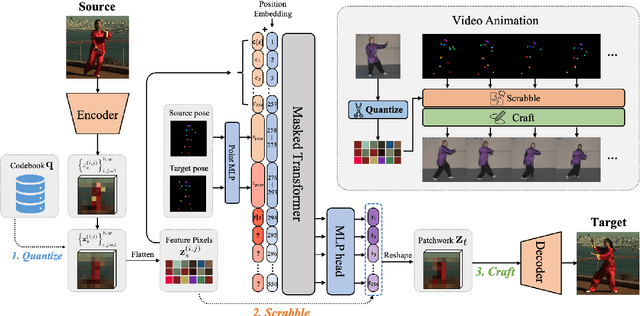
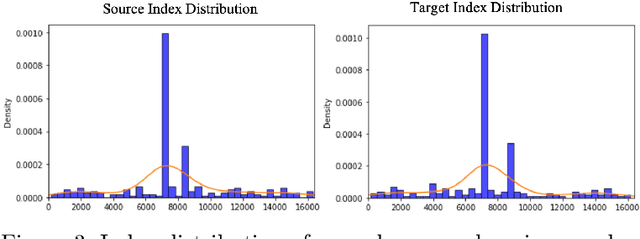
This paper studies the task of conditional Human Motion Animation (cHMA). Given a source image and a driving video, the model should animate the new frame sequence, in which the person in the source image should perform a similar motion as the pose sequence from the driving video. Despite the success of Generative Adversarial Network (GANs) methods in image and video synthesis, it is still very challenging to conduct cHMA due to the difficulty in efficiently utilizing the conditional guided information such as images or poses, and generating images of good visual quality. To this end, this paper proposes a novel model of learning to Quantize, Scrabble, and Craft (QS-Craft) for conditional human motion animation. The key novelties come from the newly introduced three key steps: quantize, scrabble and craft. Particularly, our QS-Craft employs transformer in its structure to utilize the attention architectures. The guided information is represented as a pose coordinate sequence extracted from the driving videos. Extensive experiments on human motion datasets validate the efficacy of our model.