 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQCRI Machine Translation Systems for IWSLT 16
Paper and Code
Jan 14, 2017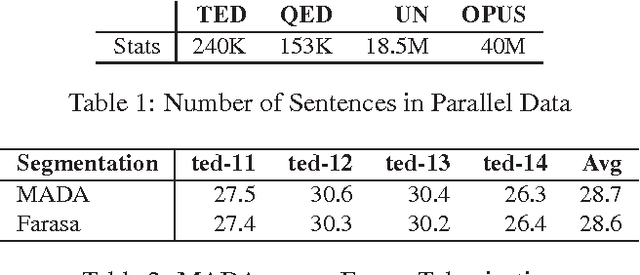
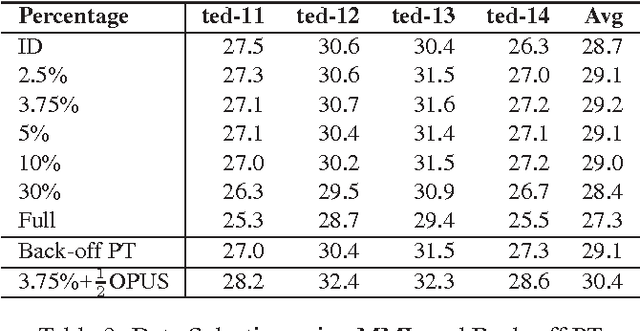
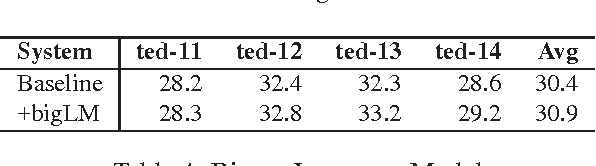

This paper describes QCRI's machine translation systems for the IWSLT 2016 evaluation campaign. We participated in the Arabic->English and English->Arabic tracks. We built both Phrase-based and Neural machine translation models, in an effort to probe whether the newly emerged NMT framework surpasses the traditional phrase-based systems in Arabic-English language pairs. We trained a very strong phrase-based system including, a big language model, the Operation Sequence Model, Neural Network Joint Model and Class-based models along with different domain adaptation techniques such as MML filtering, mixture modeling and using fine tuning over NNJM model. However, a Neural MT system, trained by stacking data from different genres through fine-tuning, and applying ensemble over 8 models, beat our very strong phrase-based system by a significant 2 BLEU points margin in Arabic->English direction. We did not obtain similar gains in the other direction but were still able to outperform the phrase-based system. We also applied system combination on phrase-based and NMT outputs.